你可以通过
stack 进行重塑,但首先需要在列中创建带有
% 和
// 的
MultiIndex。
MultiIndex 值将
Time 和
Unit 映射到第二级
MultiIndex,方法是通过
2 的整数除法(
//)进行向下取整,每个对的差异则通过模除(
%)创建。
然后,
stack 使用由
// 创建的最后一级,并在
index 中创建新的
MultiIndex 级别,这是不必要的,因此可以使用
reset_index(level=2, drop=True) 将其删除。
最后,使用
reset_index 将第一级和第二级转换为
columns。
[[1,0]] 用于交换列以更改顺序。
df = df.set_index(['ANO','MNO'])
cols = np.arange(len(df.columns))
df.columns = [cols % 2, cols // 2]
print (df)
0 1 0 1 0 1 0 1
0 0 1 1 2 2 3 3
ANO MNO
1 A 113 06/01/2010 129 06/02/2010 143 06/03/2010 209 05/04/2010
2 B 218 06/01/2010 211 06/02/2010 244 06/03/2010 348 05/04/2010
3 C 22 06/01/2010 114 06/02/2010 100 06/03/2010 151 05/04/2010
df = df.stack()[[1,0]].reset_index(level=2, drop=True).reset_index()
df.columns = ['ANO','MNO','Time','Unit']
print (df)
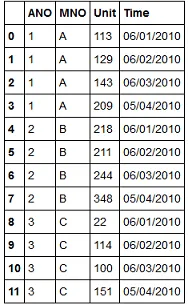
ANO MNO Time Unit
0 1 A 06/01/2010 113
1 1 A 06/02/2010 129
2 1 A 06/03/2010 143
3 1 A 05/04/2010 209
4 2 B 06/01/2010 218
5 2 B 06/02/2010 211
6 2 B 06/03/2010 244
7 2 B 05/04/2010 348
8 3 C 06/01/2010 22
9 3 C 06/02/2010 114
10 3 C 06/03/2010 100
11 3 C 05/04/2010 151
编辑:
#last column is missing
print (df)
ANO MNO UJ2010 DJ2010 UF2010 DF2010 UM2010 DM2010 UA2010
0 1 A 113 06/01/2010 129 06/02/2010 143 06/03/2010 209
1 2 B 218 06/01/2010 211 06/02/2010 244 06/03/2010 348
2 3 C 22 06/01/2010 114 06/02/2010 100 06/03/2010 151
df = df.set_index(['ANO','MNO'])
#MultiIndex is created by first character of column names with all another
df.columns = [df.columns.str[0], df.columns.str[1:]]
print (df)
U D U D U D U
J2010 J2010 F2010 F2010 M2010 M2010 A2010
ANO MNO
1 A 113 06/01/2010 129 06/02/2010 143 06/03/2010 209
2 B 218 06/01/2010 211 06/02/2010 244 06/03/2010 348
3 C 22 06/01/2010 114 06/02/2010 100 06/03/2010 151
#stack add missing values, replace them by NaN
df = df.stack().reset_index(level=2, drop=True).reset_index()
df.columns = ['ANO','MNO','Time','Unit']
print (df)
ANO MNO Time Unit
0 1 A NaN 209
1 1 A 06/02/2010 129
2 1 A 06/01/2010 113
3 1 A 06/03/2010 143
4 2 B NaN 348
5 2 B 06/02/2010 211
6 2 B 06/01/2010 218
7 2 B 06/03/2010 244
8 3 C NaN 151
9 3 C 06/02/2010 114
10 3 C 06/01/2010 22
11 3 C 06/03/2010 100
pd.lreshape的任何文档。你能否请稍微解释一下代码?还有你能否给我提供一下文档的参考资料? - pd farhadpd.lreshape ??应该会在弹出窗口中显示其底层代码。据我所知,目前它仍处于实验阶段,因此尚未包含在文档页面中。 - Nickil Maveliaccount的值。 - pd farhaddropna=False到pd.lreshape中,以匹配传递的两个列表的长度。 - Nickil Maveli