您可以使用异常理论来检测异常情况。寻找异常值的一种非常天真的方法是使用
mahalanobis距离。这是一种考虑到数据分布的度量,并计算相对于中心的距离。它可以解释为文章距离中心有多少个标准偏差。然而,这也将包括真正非常受欢迎的文章,但它给出了第一个指示,表明某些内容很奇怪。
第二种更普遍的方法是建立模型。您可以对用户可操作的变量和与编辑相关的变量进行回归。人们会期望用户和编辑在某种程度上达成一致。如果他们没有达成一致,则再次表明存在异常情况。
在这两种情况下,你需要定义一些阈值并尝试找到基于此的一些加权。一种可能的方法是使用平方根马氏距离作为反向权重。如果你远离中心,你的分数将会下降。同样的方法也可以使用模型残差。在这里,你甚至可以考虑符号。如果编辑得分低于基于用户得分预期的得分,残差将为负。如果编辑得分高于基于用户得分预期的得分,残差为正,并且文章很可能没有被操纵。这使你可以定义一些规则来重新加权给定的分数。
R语言示例:
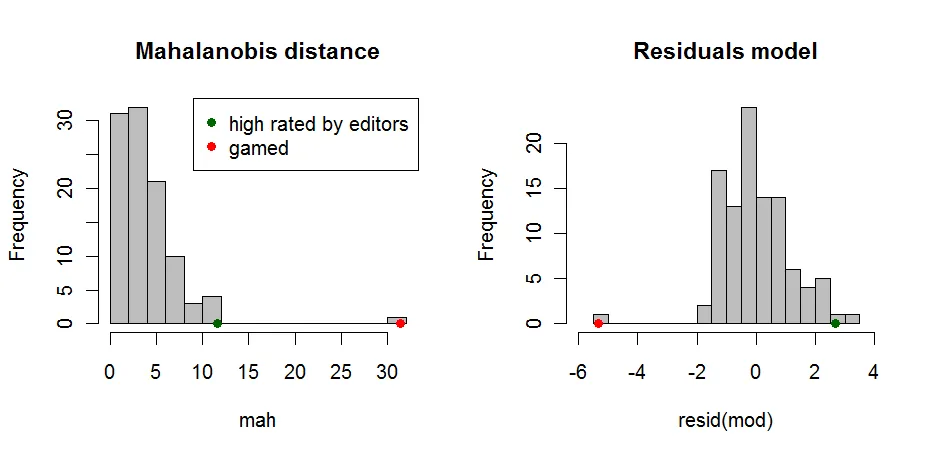
代码:
test <- data.frame(
quoted = rpois(100,12),
seen = rbinom(100,60,0.3),
download = rbinom(100,30,0.3)
)
test <- within(test,{
editorial = round((quoted+seen+download)/10+rpois(100,1))
})
test[101,]<-c(20,18,13,0)
test[102,]<-c(20,18,13,8)
mah <- mahalanobis(test,colMeans(test),cov(test))
mod <- lm(editorial~quoted*seen*download,data=test)
op <- par(mfrow=c(1,2))
hist(mah,breaks=20,col="grey",main="Mahalanobis distance")
points(mah[101],0,col="red",pch=19)
points(mah[102],0,,col="darkgreen",pch=19)
legend("topright",legend=c("high rated by editors","gamed"),
pch=19,col=c("darkgreen","red"))
hist(resid(mod),breaks=20,col="grey",main="Residuals model",xlim=c(-6,4))
points(resid(mod)[101],0,col="red",pch=19)
points(resid(mod)[102],0,,col="darkgreen",pch=19)
par(op)