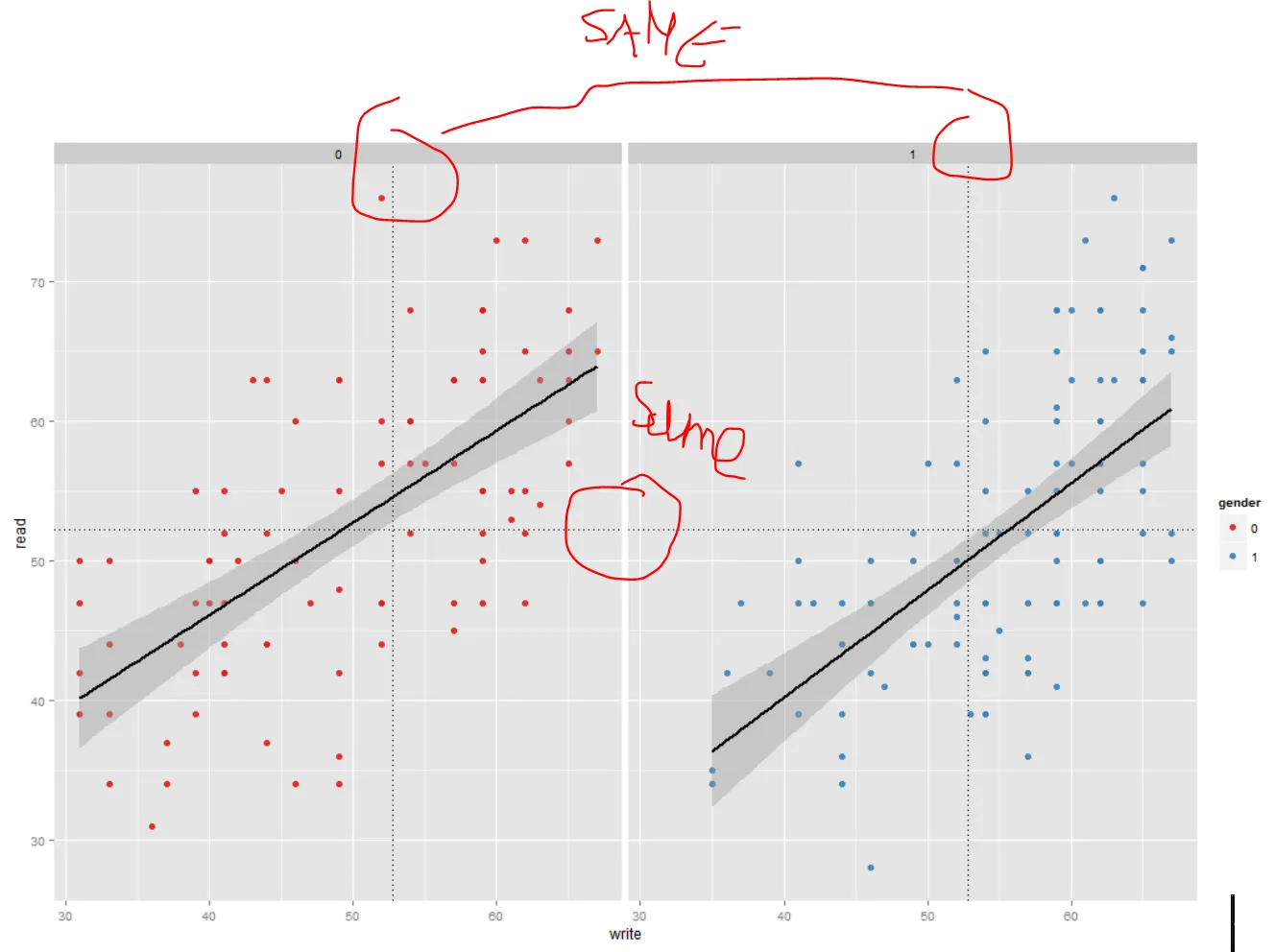
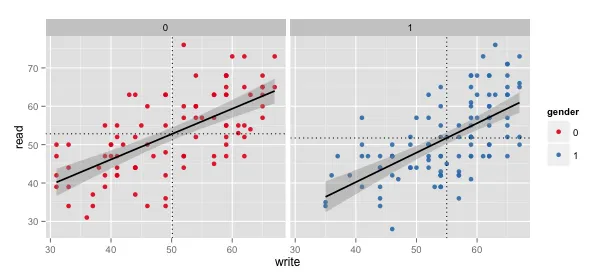
我希望能够使用ggplot获取子集(x轴和y轴)的分面子集均值。然而,我得到的是数据的平均值而不是子集的平均值。我不知道如何解决这个问题。
hsb2<-read.table("http://www.ats.ucla.edu/stat/data/hsb2.csv", sep=",", header=T)
head(hsb2)
hsb2$gender = as.factor(hsb2$female)
ggplot() +
geom_point(aes(y = read,x = write,colour = gender),data=hsb2,size = 2.2,alpha = 0.9) +
scale_colour_brewer(guide = guide_legend(),palette = 'Set1') +
stat_smooth(aes(x = write,y = read),data=hsb2,colour = '#000000',size = 0.8,method = lm,formula = 'y ~ x') +
geom_vline(aes(xintercept = mean(write)),data=hsb2,linetype = 3) +
geom_hline(aes(yintercept = mean(read)),data=hsb2,linetype = 3) +
facet_wrap(facets = ~gender)