这是我对问题的看法。我会给你一个大致的概述,然后展示我的C++实现。主要想法是我想从左到右、从上到下处理图像。我将在找到每个blob(或轮廓)时进行处理,但是为了实现成功的(有序的)分割,我需要一些中间步骤。
第一步是尝试按行对blobs进行排序-这意味着每行都有一组(无序的)水平blobs。这没关系。第一步是计算某种垂直排序,如果我们从上到下处理每行,我们将实现这一点。
当blobs通过行(垂直)排序后,我就可以检查它们的质心(或重心)并对它们进行水平排序。想法是我将逐行处理,并为每行对blob质心进行排序。让我们看一下我想在这里实现什么样的例子。
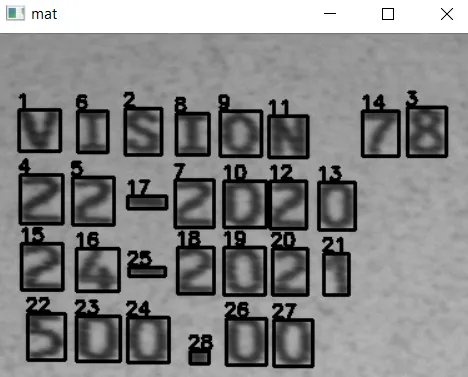
这是您的输入图像:
这是我称之为“行掩码”的内容:
最后一个图像包含代表每个“行”的白色区域。每一行都有一个编号(例如Row1,Row2等),每一行都包含一组blobs(或字符,在这种情况下)。通过从上到下处理每一行,您已经在垂直轴上对blobs进行了排序。
如果我从上到下给每行编号,我会得到这张图片:
行掩码是创建“blob行”的一种方法,可以通过形态学计算获得。查看叠加在一起的2个图像以便更好地查看处理顺序:
我们要做的第一件事是垂直排序(蓝箭头),然后我们将解决水平排序(红箭头)。您可以看到通过逐行处理,我们可能会克服排序问题!
使用质心进行水平排序。
现在让我们看看如何水平排序这些斑点。如果我们创建一个简化图片,宽度等于输入图片的宽度,高度等于
行掩模中的
行数,我们可以简单地重叠每个斑点质心的每个水平坐标(x坐标)。看看这个例子:

这是一个
行表。 每行代表在
行掩模中找到的行数,并且从上到下进行阅读。表的宽度与输入图像的宽度相同,
在空间上对应水平轴。 每个
方格都是输入图像中的像素,仅使用水平坐标将其映射到行表中(因为我们对行的简化非常直观)。 行表中每个像素的实际值是一个
标签,用于标记输入图像上的每个斑点。请注意,标签没有顺序!
例如,此表显示,在
第1行(您已经知道第1行是什么 - 它是
行掩模上的第一片白色区域)的位置
(1,4)处有斑点号码
3。 在位置
(1,6)处有斑点号码
2,依此类推。我认为这个表很棒的一点是您可以遍历它,并且对于每个不同于
0的值,水平排序变得非常简单。这是左到右的行表排序:
 将斑点信息映射到质心
将斑点信息映射到质心
我们将使用斑点的
质心来
映射在两个表示(行掩模/行表)之间的信息。假设您已经有了两个“辅助”图像,并且一次处理输入图像上的每个斑点(或轮廓)。例如,您开始时有以下内容:

好吧,这里有一个斑点。我们如何将其映射到
行掩模和
行表中?使用其
质心。如果我们计算质心(在图中显示为绿点),则可以构建一个质心和标签的
字典。例如,对于此斑点,
质心位于
(271,193)。好的,让我们分配
标签= 1。因此,我们现在有了这个字典:
现在,我们使用行掩模上相同的质心来查找此 Blob 所在的行。类似于这样:
rowNumber = rowMask.at( 271,193 )
这个操作应该返回 rownNumber = 3。很好!我们知道了我们的 blob 在哪一行,因此它现在是垂直排列的。现在,让我们将它的水平坐标存储在行表中:
rowTable.at( 271, 193 ) = 1
现在,
rowTable(在其行和列中)保存了已处理斑点的标签。行表应该是这样的:

这个表要更宽一些,因为它的水平维度必须与输入图像相同。在这张图片中,
label 1 被放在
Column 271,Row 3 。如果这是您图像上唯一的斑点,则斑点已经排好序了。但是,如果您在例如
Column 2,
Row 1 中添加另一个斑点,会发生什么?那就是为什么在处理所有斑点之后需要重新遍历此表,以正确地更正它们的标签。
C++实现:
好了,算法应该有点清晰了(如果不清楚,请问我)。我将尝试使用C++和OpenCV实现这些想法。首先,我需要您输入的二进制图像,计算使用Otsu阈值法很容易:
std::string imageName = "C://opencvImages//yFX3M.png";
cv::Mat testImage = cv::imread( imageName );
cv::Mat grayImage;
cv::cvtColor( testImage, grayImage, cv::COLOR_RGB2GRAY );
cv::Mat binImage;
cv::threshold( grayImage, binImage, 0, 255, cv::THRESH_OTSU );
binImage = 255 - binImage;
这是生成的二进制图像,没有花哨的东西,只是我们开始工作所需的基本内容:

第一步是获取“行掩码”。可以使用形态学实现。只需将具有非常大水平“结构元素”的膨胀+腐蚀应用于图像。想法是将那些斑块水平地“熔合”成矩形:
cv::Mat rowMask = binImage.clone();
int horizontalSize = 100;
cv::Mat SE = cv::getStructuringElement( cv::MORPH_RECT, cv::Size(horizontalSize,1) );
cv::morphologyEx( rowMask, rowMask, cv::MORPH_DILATE, SE, cv::Point(-1,-1), 2 );
cv::morphologyEx( rowMask, rowMask, cv::MORPH_ERODE, SE, cv::Point(-1,-1), 1 );
这将导致以下行掩码:

非常酷,现在我们有了行掩码,我们必须给它们编上号,对吧?有很多方法可以做到这一点,但现在我只对简单的方法感兴趣:遍历此图像并获取每个像素。如果一个像素是白色的,则使用泛洪填充(Flood Fill)操作将该部分图像标记为唯一的块(或行,在本例中)。这可以按以下方式完成:
int rowCount = 0;
for( int y = 0; y < rowMask.rows; y++ ){
for( int x = 0; x < rowMask.cols; x++ ){
uchar currentPixel = rowMask.at<uchar>( y, x );
if ( currentPixel == 255 ) {
rowCount++;
cv::floodFill( rowMask, cv::Point( x, y ), rowCount, (cv::Rect*)0, cv::Scalar(), 0 );
}
}
}
这个过程将会把所有行从
1到
r标记上标签。这正是我们想要的结果。如果你查看图片,你会模糊地看到这些行,那是因为我们的标签对应灰度像素非常低的值。
好的,现在让我们准备
行表格。这个“表格”实际上只是另一张图片,记住:它的宽度与输入图像相同,高度等于在
行掩膜上计算的行数:
cv::Mat rowTable = cv::Mat::zeros( cv::Size(binImage.cols, rowCount), CV_8UC1 );
rowTable = 255 - rowTable;
这里,我只是为了方便翻转了最终图像。因为我想实际看到表格如何被填充(非常低强度的)像素,并确保一切按预期工作。
现在来到有趣的部分。我们已经准备好了两张图片(或数据容器)。我们需要单独处理每个 blob。思路是从二进制图像中提取每个 blob/ 轮廓/ 字符,计算其质心并指定一个新的标签。再次说明,有很多方法可以做到这一点。在这里,我使用以下方法:
我将循环遍历二进制掩模。我将从此二进制输入中获取当前最大的blob。我将计算其质心,并将其数据存储在所需的每个容器中,然后,我将从掩模中删除该 blob。我将重复该过程,直到没有更多的 blobs 为止。这是我的做法,特别是因为我已经为此编写了函数。这是我的方法:
//Prepare a couple of dictionaries for data storing:
std::map< int, cv::Point > blobMap; //holds label, gives centroid
std::map< int, cv::Rect > boundingBoxMap; //holds label, gives bounding box
首先,有两个字典。一个接收一个blob标签并返回质心。另一个接收相同的标签并返回边界框。
cv::Mat bobFilterInput = binImage.clone();
int blobLabel = 0;
bool extractBlobs = true;
int currentBlob = 0;
while ( extractBlobs ){
cv::Mat biggestBlob = findBiggestBlob( bobFilterInput );
cv::Moments momentStructure = cv::moments( biggestBlob, true );
float cx = momentStructure.m10 / momentStructure.m00;
float cy = momentStructure.m01 / momentStructure.m00;
cv::Point blobCentroid;
blobCentroid.x = cx;
blobCentroid.y = cy;
boundingBox boxData;
computeBoundingBox( biggestBlob, boxData );
cv::Rect cropBox = boundingBox2Rect( boxData );
blobLabel++;
blobMap.emplace( blobLabel, blobCentroid );
boundingBoxMap.emplace( blobLabel, cropBox );
int blobRow = rowMask.at<uchar>( cy, cx );
blobRow--;
rowTable.at<uchar>( blobRow, cx ) = blobLabel;
cv::Mat blobDifference = bobFilterInput - biggestBlob;
int pixelsLeft = cv::countNonZero( blobDifference );
bobFilterInput = blobDifference;
if ( pixelsLeft <= 0 ){
extractBlobs = false;
}
currentBlob++;
}
观看下面这个漂亮的动画,展示了如何处理每个blob,对其进行处理并删除,直到一个都不剩:

现在,关于上面的代码片段,我有一些辅助函数:biggestBlob和computeBoundingBox。这些函数分别计算二进制图像中最大的blob,以及将自定义的bounding box结构体转换为OpenCV的Rect结构体。这些是这些函数所执行的操作。
这个代码片段的核心是:一旦你有了一个被隔离的blob,就要计算它的质心(实际上我通过central moments计算重心)。生成一个新的label。将这个label和centroid存储在一个dictionary中,在我的情况下,是blobMap字典。此外,计算bounding box并将其存储在另一个dictionary中,即boundingBoxMap:
//Label blob:
blobLabel++;
blobMap.emplace( blobLabel, blobCentroid );
boundingBoxMap.emplace( blobLabel, cropBox );
现在,使用centroid数据,fetch该blob的对应row。一旦你获得了这一行,将此数字存储到你的行表中:
//Get the row for this centroid
int blobRow = rowMask.at<uchar>( cy, cx );
blobRow
//Place centroid on rowed image:
rowTable.at<uchar>( blobRow, cx ) = blobLabel;
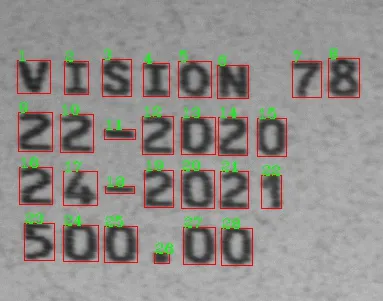
非常好。此时您已经准备好了行表格。让我们循环遍历它并最终对这些可恶的 blob 进行排序:
int blobCounter = 1;
for( int y = 0; y < rowTable.rows; y++ ){
for( int x = 0; x < rowTable.cols; x++ ){
uchar currentLabel = rowTable.at<uchar>( y, x );
if ( currentLabel != 255 ){
cv::Rect currentBoundingBox = boundingBoxMap[ currentLabel ];
cv::rectangle( testImage, currentBoundingBox, cv::Scalar(0,255,0), 2, 8, 0 );
std::string counterString = std::to_string( blobCounter );
cv::putText( testImage, counterString, cv::Point( currentBoundingBox.x, currentBoundingBox.y-1 ),
cv::FONT_HERSHEY_SIMPLEX, 0.7, cv::Scalar(255,0,0), 1, cv::LINE_8, false );
blobCounter++;
}
}
}
没有花哨的东西,只是一个普通的嵌套 for 循环,遍历每个在 行表 上的像素。如果像素不同于白色,则使用 标签 检索出 质心 和 边界框,并将 标签 更改为递增的数字。为了显示结果,我只需在原始图像上绘制边界框和新标签。
查看此动画中的有序处理:

非常酷,这里还有一个奖励动画,行表用水平坐标填充:










.或-,它还能正常工作吗? - Jimit Vaghela