我有一个包含多年数据的宽数据框:
df = pd.DataFrame(index=pd.Index([29925, 223725, 280165, 813285, 956765], name='ID'),
columns=pd.Index([1991, 1992, 1993, 1994, 1995, 1996, '2010-2012'], name='Year'),
data = np.array([[np.NaN, np.NaN, 16, 17, 18, 19, np.NaN],
[16, 17, 18, 19, 20, 21, np.NaN],
[np.NaN, np.NaN, np.NaN, np.NaN, 16, 17, 31],
[np.NaN, 22, 23, 24, np.NaN, 26, np.NaN],
[36, 36, 37, 38, 39, 40, 55]]))
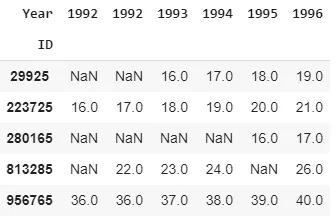
Year 1991 1992 1993 1994 1995 1996 2010-2012
ID
29925 NaN NaN 16.0 17.0 18.0 19.0 NaN
223725 16.0 17.0 18.0 19.0 20.0 21.0 NaN
280165 NaN NaN NaN NaN 16.0 17.0 31.0
813285 NaN 22.0 23.0 24.0 NaN 26.0 NaN
956765 36.0 36.0 37.0 38.0 39.0 40.0 55.0
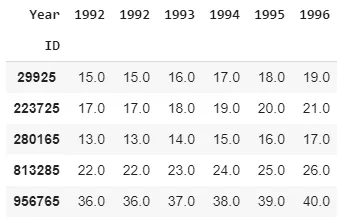
每行中的值是每个人的年龄,每个人都有一个唯一的ID。我想要根据每行现有的年龄值,在每年的每行中填充此数据帧中的
NaN。例如,ID
29925 在1993 是16岁,我们知道他们在1992 是15岁,在1991 是14岁,因此我们希望替换列1992 和1991 中29925 的NaN。同样地,我希望根据29925 的现有年龄值替换2010-2012 列中的NaN。假设29925 从1996 到2010-2012 列增加了15岁。如何以最快的方式为整个数据框架执行此操作 - 即对所有ID?