Q-learning is a technique for letting the AI learn by itself by giving it reward or punishment.
This example shows the Q-learning used for path finding. A robot learns where it should go from any state.
The robot starts at a random place, it keeps memory of the score while it explores the area, whenever it reaches the goal, we repeat with a new random start. After enough repetitions the score values will be stationary (convergence).
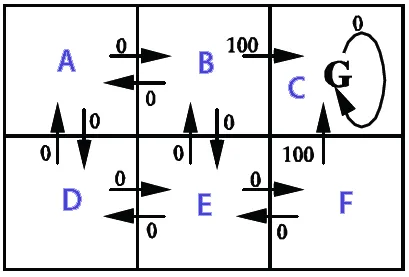
In this example the action outcome is deterministic (transition probability is 1) and the action selection is random. The score values are calculated by the Q-learning algorithm Q(s,a).
The image shows the states (A,B,C,D,E,F), possible actions from the states and the reward given.
Result Q*(s,a)
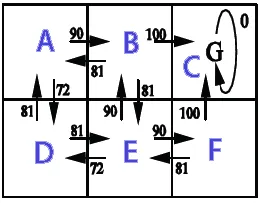
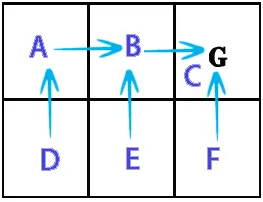
Policy Π*(s)
Qlearning.java
import java.text.DecimalFormat;
import java.util.Random;
public class Qlearning {
final DecimalFormat df = new DecimalFormat("#.##");
final double alpha = 0.1;
final double gamma = 0.9;
final int stateA = 0;
final int stateB = 1;
final int stateC = 2;
final int stateD = 3;
final int stateE = 4;
final int stateF = 5;
final int statesCount = 6;
final int[] states = new int[]{stateA,stateB,stateC,stateD,stateE,stateF};
int[][] R = new int[statesCount][statesCount];
double[][] Q = new double[statesCount][statesCount];
int[] actionsFromA = new int[] { stateB, stateD };
int[] actionsFromB = new int[] { stateA, stateC, stateE };
int[] actionsFromC = new int[] { stateC };
int[] actionsFromD = new int[] { stateA, stateE };
int[] actionsFromE = new int[] { stateB, stateD, stateF };
int[] actionsFromF = new int[] { stateC, stateE };
int[][] actions = new int[][] { actionsFromA, actionsFromB, actionsFromC,
actionsFromD, actionsFromE, actionsFromF };
String[] stateNames = new String[] { "A", "B", "C", "D", "E", "F" };
public Qlearning() {
init();
}
public void init() {
R[stateB][stateC] = 100;
R[stateF][stateC] = 100;
}
public static void main(String[] args) {
long BEGIN = System.currentTimeMillis();
Qlearning obj = new Qlearning();
obj.run();
obj.printResult();
obj.showPolicy();
long END = System.currentTimeMillis();
System.out.println("Time: " + (END - BEGIN) / 1000.0 + " sec.");
}
void run() {
Random rand = new Random();
for (int i = 0; i < 1000; i++) {
int state = rand.nextInt(statesCount);
while (state != stateC)
{
int[] actionsFromState = actions[state];
int index = rand.nextInt(actionsFromState.length);
int action = actionsFromState[index];
int nextState = action;
double q = Q(state, action);
double maxQ = maxQ(nextState);
int r = R(state, action);
double value = q + alpha * (r + gamma * maxQ - q);
setQ(state, action, value);
state = nextState;
}
}
}
double maxQ(int s) {
int[] actionsFromState = actions[s];
double maxValue = Double.MIN_VALUE;
for (int i = 0; i < actionsFromState.length; i++) {
int nextState = actionsFromState[i];
double value = Q[s][nextState];
if (value > maxValue)
maxValue = value;
}
return maxValue;
}
int policy(int state) {
int[] actionsFromState = actions[state];
double maxValue = Double.MIN_VALUE;
int policyGotoState = state;
for (int i = 0; i < actionsFromState.length; i++) {
int nextState = actionsFromState[i];
double value = Q[state][nextState];
if (value > maxValue) {
maxValue = value;
policyGotoState = nextState;
}
}
return policyGotoState;
}
double Q(int s, int a) {
return Q[s][a];
}
void setQ(int s, int a, double value) {
Q[s][a] = value;
}
int R(int s, int a) {
return R[s][a];
}
void printResult() {
System.out.println("Print result");
for (int i = 0; i < Q.length; i++) {
System.out.print("out from " + stateNames[i] + ": ");
for (int j = 0; j < Q[i].length; j++) {
System.out.print(df.format(Q[i][j]) + " ");
}
System.out.println();
}
}
void showPolicy() {
System.out.println("\nshowPolicy");
for (int i = 0; i < states.length; i++) {
int from = states[i];
int to = policy(from);
System.out.println("from "+stateNames[from]+" goto "+stateNames[to]);
}
}
}
Print result
out from A: 0 90 0 72,9 0 0
out from B: 81 0 100 0 81 0
out from C: 0 0 0 0 0 0
out from D: 81 0 0 0 81 0
out from E: 0 90 0 72,9 0 90
out from F: 0 0 100 0 81 0
showPolicy
from a goto B
from b goto C
from c goto C
from d goto A
from e goto B
from f goto C
Time: 0.025 sec.
