我使用statsmodels中的ARIMA模型输出的结果不准确。我想知道是否有人能够帮助我理解我的代码存在什么问题。
以下是示例:
import pandas as pd
import numpy as np
import datetime as dt
from statsmodels.tsa.arima_model import ARIMA
# Setting up a data frame that looks twenty days into the past,
# and has linear data, from approximately 1 through 20
counts = np.arange(1, 21) + 0.2 * (np.random.random(size=(20,)) - 0.5)
start = dt.datetime.strptime("1 Nov 01", "%d %b %y")
daterange = pd.date_range(start, periods=20)
table = {"count": counts, "date": daterange}
data = pd.DataFrame(table)
data.set_index("date", inplace=True)
print data
count
date
2001-11-01 0.998543
2001-11-02 1.914526
2001-11-03 3.057407
2001-11-04 4.044301
2001-11-05 4.952441
2001-11-06 6.002932
2001-11-07 6.930134
2001-11-08 8.011137
2001-11-09 9.040393
2001-11-10 10.097007
2001-11-11 11.063742
2001-11-12 12.051951
2001-11-13 13.062637
2001-11-14 14.086016
2001-11-15 15.096826
2001-11-16 15.944886
2001-11-17 17.027107
2001-11-18 17.930240
2001-11-19 18.984202
2001-11-20 19.971603
剩下的代码设置了ARIMA模型。
# Setting up ARIMA model
order = (2, 1, 2)
model = ARIMA(data, order, freq='D')
model = model.fit()
print model.predict(1, 20)
2001-11-02 1.006694
2001-11-03 1.056678
2001-11-04 1.116292
2001-11-05 1.049992
2001-11-06 0.869610
2001-11-07 1.016006
2001-11-08 1.110689
2001-11-09 0.945190
2001-11-10 0.882679
2001-11-11 1.139272
2001-11-12 1.094019
2001-11-13 0.918182
2001-11-14 1.027932
2001-11-15 1.041074
2001-11-16 0.898727
2001-11-17 1.078199
2001-11-18 1.027331
2001-11-19 0.978840
2001-11-20 0.943520
2001-11-21 1.040227
Freq: D, dtype: float64
你可以看到,数据只是在 1左右波动,而没有上升。我做错了什么?
(附带说明,由于某些原因,我无法将字符串日期 "2001-11-21"传递给预测函数。了解原因会很有帮助。)
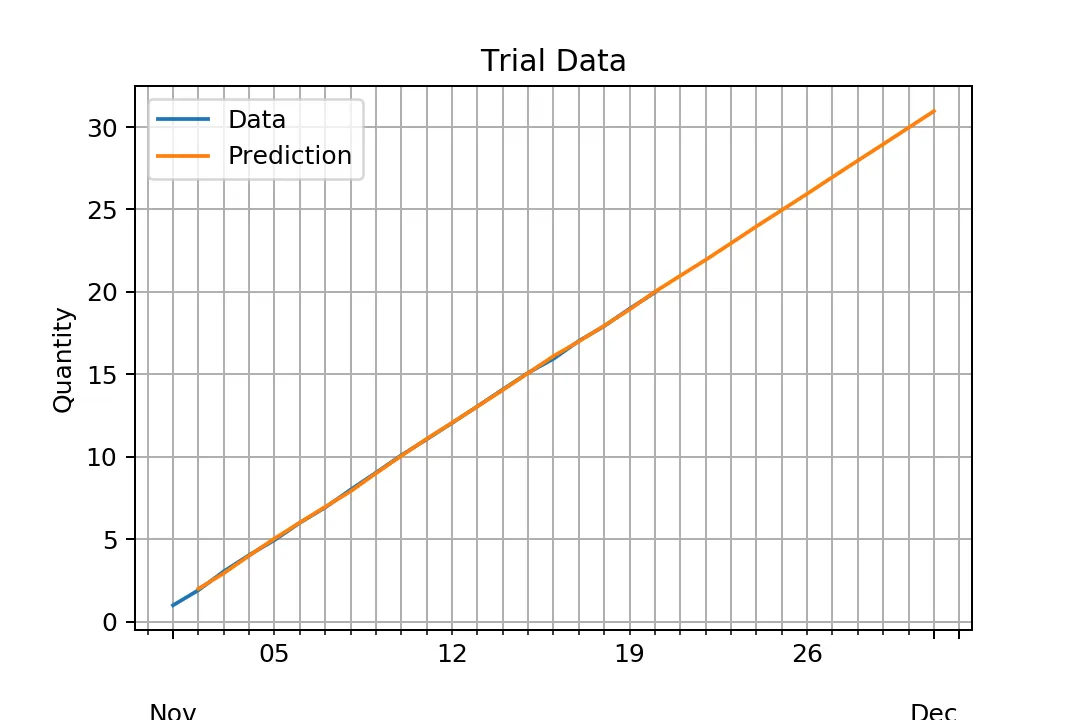
typ='level'。请参阅 https://dev59.com/Borda4cB1Zd3GeqPOZv8 和 predict docstring。也可以直接向模型添加趋势(目前是拟合)。 - JosefARIMA.predict的文档说明。这可能是统计学中的一个概念。 - hlin117typ='levels',而不是type='level'。也许过去是'level',但文档显示typ : str {‘linear’, ‘levels’}。 - Jarad