也许考虑尝试这种方法,因为它是我从Jason Brownlee博士的Machine Learning Mastery学习到的方法的结合。
https://machinelearningmastery.com/arima-for-time-series-forecasting-with-python/
和Farhad Malik,数学家
https://towardsdatascience.com/forecasting-exchange-rates-using-arima-in-python-f032f313fc56
通过结合他们的方法和技术,我成功地创造出了一个接近可行和可靠模型。以下是我辛苦拼凑数小时的代码:
import warnings
import pandas as pd
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error
from math import sqrt
from matplotlib import pyplot
rollRate=[0.3469842191781748,0.9550689157572028,0.48170862494888256,0.15277985674197356,0.46102487817508747,0.32777706854320243,
0.5163787896482797,0.01707716528127215,0.015036662424309755,0.2299825242910243,0.03719773802216722,0.24392098372995807,
0.1783587055969874,0.6759904243574179,0.1197617555878022,
0.04274682226635633,0.27369984820298465,0.18999355015483932,0.2985208240580264,0.2872064881442138,1.0522764728046277,
0.3694114556631419,0.09613536093441034,0.6648215681632191,0.3223120091564835,0.9274048223872483,0.2763221143255601,
0.4501460109958479,0.2220472247972312,0.3644512582291407,0.7790042237519584,0.3749145302678043,
1.2771681290160286,0.6760112486224217,0.5214358465170098,0.84041997296269,0.12054593136059581,
0.18900376737686622,0.042561102427304424,0.17189805124670604,0.11383752243305952,0.2687780002387387,
0.717538770963329,0.26636160206108384,0.04221743047344771,0.3259506533106764,0.20146525340606328,0.4059344185647537,
0.07503287726465639,0.3011594076817088,0.1433563136989911,0.14803562944375281,0.23096999679467808,
0.31133672787599703,0.2313639154827471,0.30343086620083537,0.4608439884577555,0.19149827372467804,
0.2506814947310181,1.008458195025946,0.3776434264127751,0.344728062930179,0.2110402015365776,0.26582041849423843,
1.1019000121595244,0.0,0.023068095385979804,0.014256779894199491,0.3209225608633755,0.00294468492742426,0.0,
0.3346732726544143,0.38256681208088283,0.4916019617068597,0.06922156984602362,0.34458053250016984,0.0,
0.09615667784109984,1.8271531669931351,0,0,0.0,0,0.0,0.03205594450156685,0.0,0.0,0.0,0,0.0,0,0.0,0,0,1.0,0]
def evaluate_arima_model(X, arima_order):
X = X.astype('float32')
train_size = int(len(X) * 0.50)
train, test = X[0:train_size], X[train_size:]
history = [x for x in train]
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=arima_order)
model_fit = model.fit(trend='nc', disp=0)
yhat = model_fit.forecast()[0]
predictions.append(yhat)
history.append(test[t])
rmse = sqrt(mean_squared_error(test, predictions))
return rmse
def evaluate_models(dataset, p_values, d_values, q_values):
dataset = dataset.astype('float32')
best_score, best_cfg = float("inf"), None
for p in p_values:
for d in d_values:
for q in q_values:
order = (p, d, q)
try:
rmse = evaluate_arima_model(dataset, order)
print(rmse)
if rmse < best_score:
best_score, best_cfg = rmse, order
print('ARIMA%s RMSE=%.3f' % (order, rmse))
except:
continue
print('Best ARIMA%s RMSE=%.3f' % (best_cfg, best_score))
p_values = range(0, 2)
d_values = range(0, 1)
q_values = range(0, 2)
warnings.filterwarnings("ignore")
dataset = pd.Series([356,386,397,397,413,458,485,344,390,360,420,435,439,454,462,454,469,500,492,473,458,469,481,
488,466,462,473,530,662,651,587,515,526,503,503,503,515,522,492,503,503,450,432,432,458,462,
503,488,466,492,503,515,500,522,575,583,587,628,640,609,606,632,617,613,598,575,564,549,538,
568,575,579,587,602,594,587,587,625,613])
dataset = dataset.values
print('\n==============================\n')
evaluate_models(dataset, p_values, d_values, q_values)
pp = 2
dd = 1
qq = 2
def StartProducingARIMAForecastValues(dataVals, p, d, q):
model = ARIMA(dataVals, order=(p, d, q))
model_fit = model.fit(disp=0)
pred = model_fit.forecast()[0]
return pred
print('\n==============================\n')
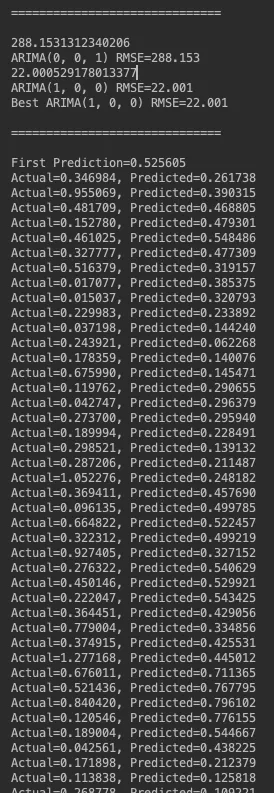
predictions = StartProducingARIMAForecastValues(rollRate, 1, 1, 0)
print('First Prediction=%f' % (predictions))
Actual = [x for x in rollRate]
Predictions = list()
for timestamp in range(len(rollRate)):
ActualValue = rollRate[timestamp]
Prediction = StartProducingARIMAForecastValues(Actual, 3, 1, 0)
print('Actual=%f, Predicted=%f' % (ActualValue, Prediction))
Predictions.append(Prediction)
Actual.append(ActualValue)
Error = mean_squared_error(rollRate, Predictions)
print('Test Mean Squared Error : %.3f' % Error)
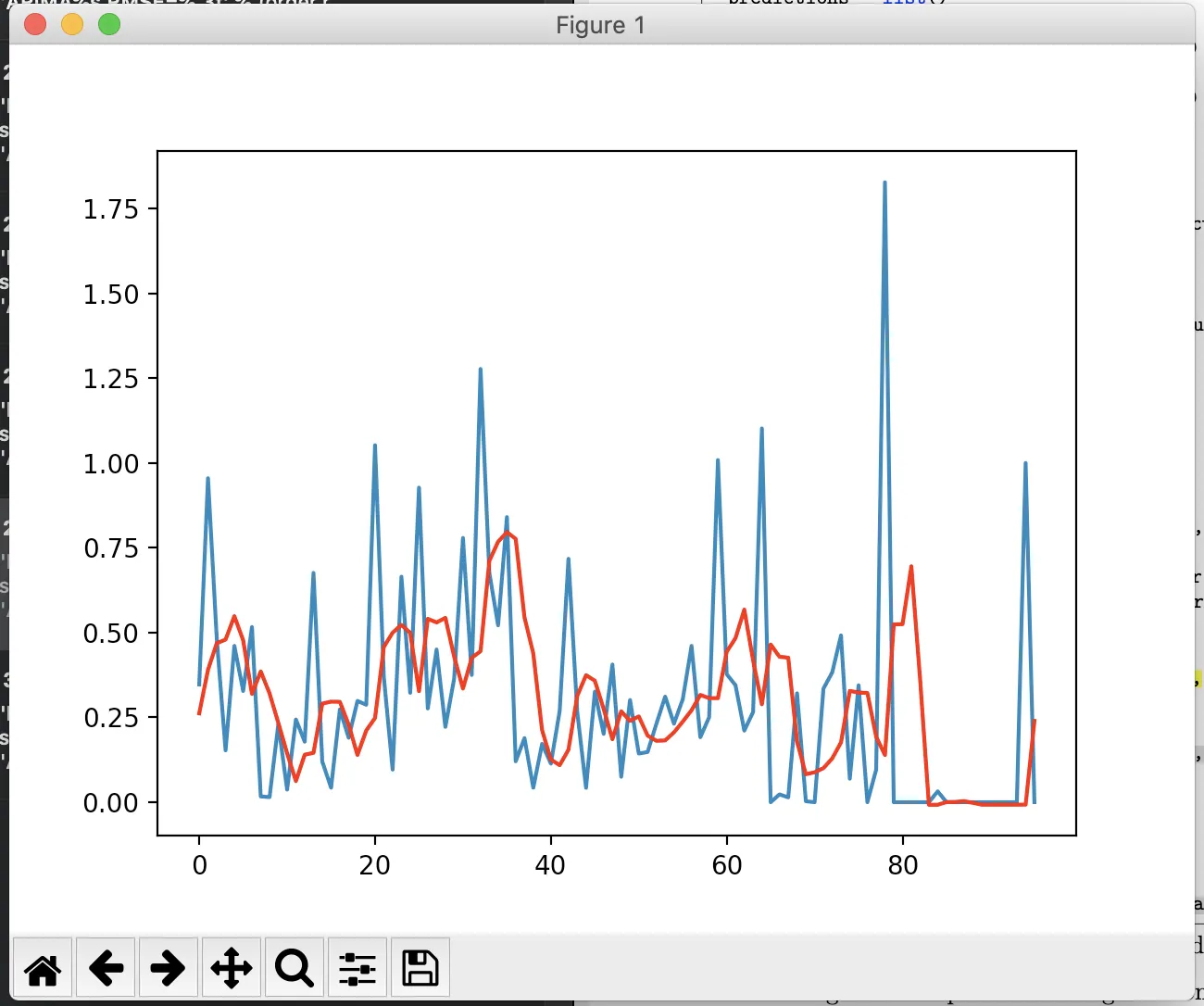
pyplot.plot(rollRate)
pyplot.plot(Predictions, color='red')
pyplot.show()
和输出图形:
和输出本身:

try-except块中简单地捕获LinAlgError?这样你就接受了对于某些参数组合,你选择的模型无法拟合的情况。 - celtry: fit = statsmodels.api.tsa.ARIMA(rollRate, (p,d,q)).fit(transparams=False) except (ValueError, LinAlgError): pass但是我遇到了一个错误:NameError: name 'LinAlgError' is not defined。 - asdfLinAlgError导入你的命名空间:from numpy.linalg import LinAlgError。 - cel_safe_arma_fit函数里看到我采用的方法。它还处理了由于起始参数不良导致的非收敛情况。但都比较幼稚。https://github.com/statsmodels/statsmodels/blob/master/statsmodels/tsa/stattools.py#L935 - jseabold_safe_arma_fit工作了吗? - bicepjai