我是在Databricks中学习Pyspark。我想生成一个相关性热图。假设这是我的数据:
myGraph=spark.createDataFrame([(1.3,2.1,3.0),
(2.5,4.6,3.1),
(6.5,7.2,10.0)],
['col1','col2','col3'])
以下是我的代码:
import pyspark
from pyspark.sql import SparkSession
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from ggplot import *
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.stat import Correlation
from pyspark.mllib.stat import Statistics
myGraph=spark.createDataFrame([(1.3,2.1,3.0),
(2.5,4.6,3.1),
(6.5,7.2,10.0)],
['col1','col2','col3'])
vector_col = "corr_features"
assembler = VectorAssembler(inputCols=['col1','col2','col3'],
outputCol=vector_col)
myGraph_vector = assembler.transform(myGraph).select(vector_col)
matrix = Correlation.corr(myGraph_vector, vector_col)
matrix.collect()[0]["pearson({})".format(vector_col)].values
目前为止,我可以得到相关矩阵。结果看起来像这样:

现在我的问题是:
- 如何将矩阵转换为数据框?我尝试了How to convert DenseMatrix to spark DataFrame in pyspark?和How to get correlation matrix values pyspark的方法,但对我没用。
- 如何生成类似于以下图片的相关热力图:
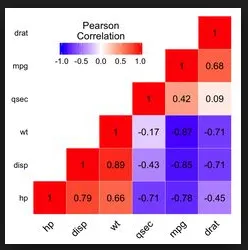
因为我刚学习pyspark和databricks。对于我的问题,ggplot或matplotlib都可以。