我想编写一个程序,广泛利用BLAS和LAPACK线性代数功能。由于性能是一个问题,我进行了一些基准测试,并想知道我采取的方法是否合法。
我有三个参赛者,想要通过一个简单的矩阵乘法来测试它们的性能。这三个参赛者分别是:
- Numpy,仅使用“点”功能。
- Python,通过共享对象调用BLAS功能。
- C++,通过共享对象调用BLAS功能。
场景
我为不同维度的矩阵乘法实现了代码,其中i从5到500,间隔为5,矩阵m1和m2设置如下:
m1 = numpy.random.rand(i,i).astype(numpy.float32)
m2 = numpy.random.rand(i,i).astype(numpy.float32)
1. Numpy
所使用的代码如下:
tNumpy = timeit.Timer("numpy.dot(m1, m2)", "import numpy; from __main__ import m1, m2")
rNumpy.append((i, tNumpy.repeat(20, 1)))
2. Python,通过共享对象调用BLAS
使用该函数
_blaslib = ctypes.cdll.LoadLibrary("libblas.so")
def Mul(m1, m2, i, r):
no_trans = c_char("n")
n = c_int(i)
one = c_float(1.0)
zero = c_float(0.0)
_blaslib.sgemm_(byref(no_trans), byref(no_trans), byref(n), byref(n), byref(n),
byref(one), m1.ctypes.data_as(ctypes.c_void_p), byref(n),
m2.ctypes.data_as(ctypes.c_void_p), byref(n), byref(zero),
r.ctypes.data_as(ctypes.c_void_p), byref(n))
测试代码如下:
r = numpy.zeros((i,i), numpy.float32)
tBlas = timeit.Timer("Mul(m1, m2, i, r)", "import numpy; from __main__ import i, m1, m2, r, Mul")
rBlas.append((i, tBlas.repeat(20, 1)))
3. c++,通过共享对象调用BLAS库
现在c++代码自然会比较长,所以我将信息减少到最少。
我使用以下代码加载函数:
void* handle = dlopen("libblas.so", RTLD_LAZY);
void* Func = dlsym(handle, "sgemm_");
我使用 gettimeofday 来测量时间,代码如下:
gettimeofday(&start, NULL);
f(&no_trans, &no_trans, &dim, &dim, &dim, &one, A, &dim, B, &dim, &zero, Return, &dim);
gettimeofday(&end, NULL);
dTimes[j] = CalcTime(start, end);
其中j是一个循环,运行20次。我使用下面的代码计算经过的时间:
double CalcTime(timeval start, timeval end)
{
double factor = 1000000;
return (((double)end.tv_sec) * factor + ((double)end.tv_usec) - (((double)start.tv_sec) * factor + ((double)start.tv_usec))) / factor;
}
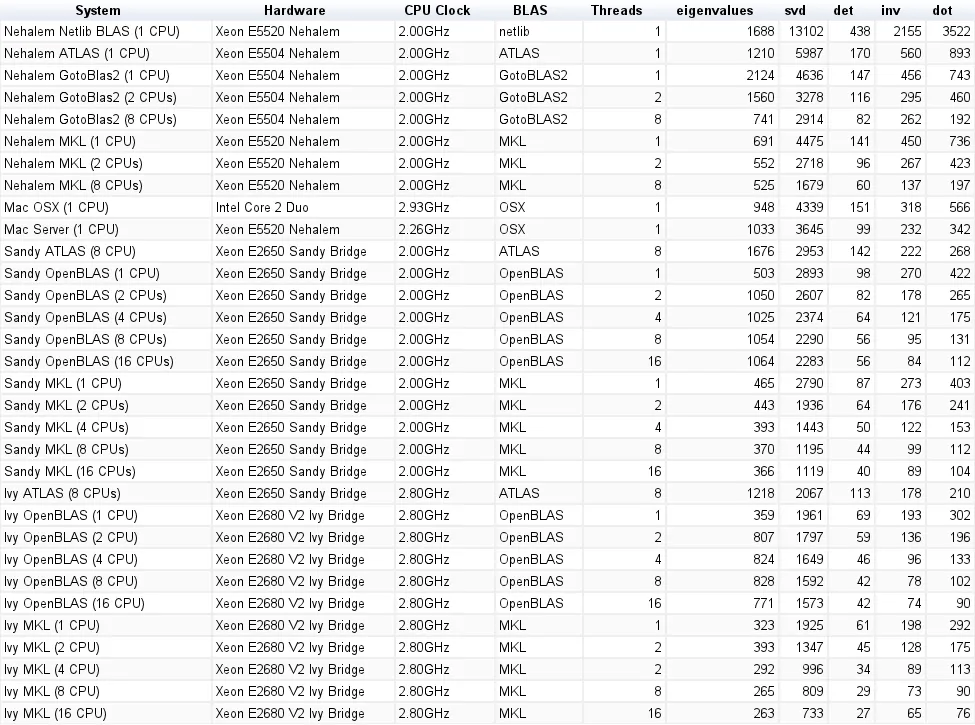
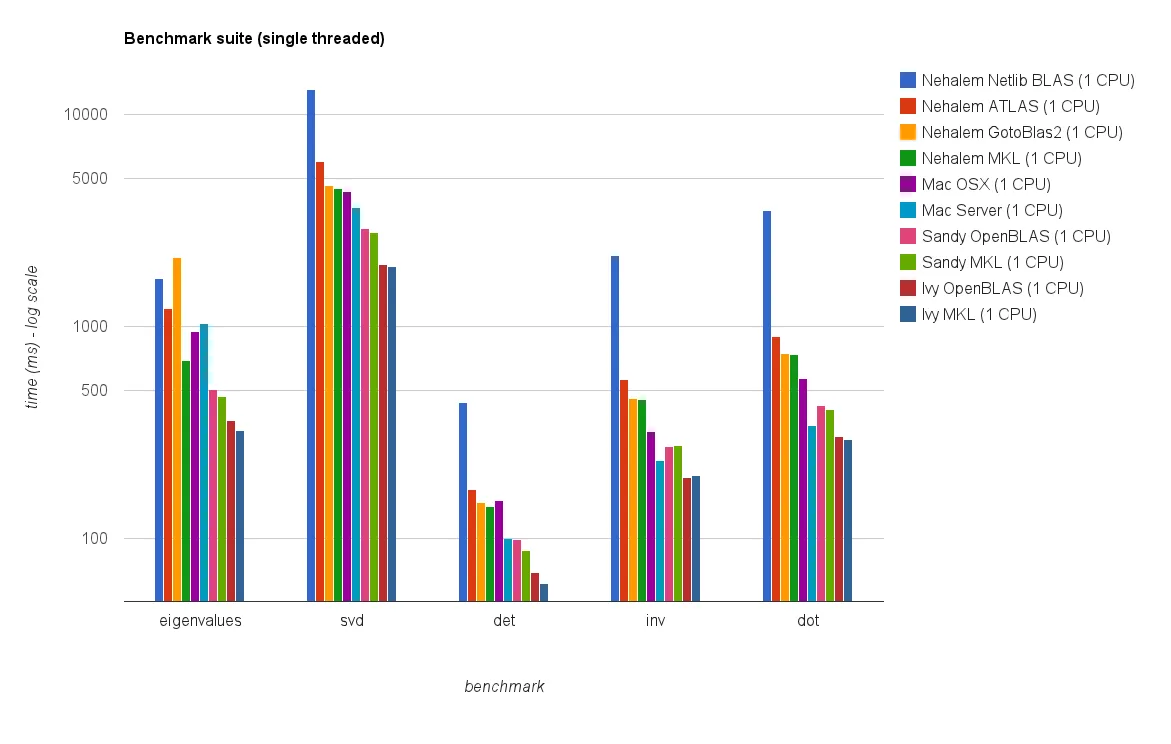
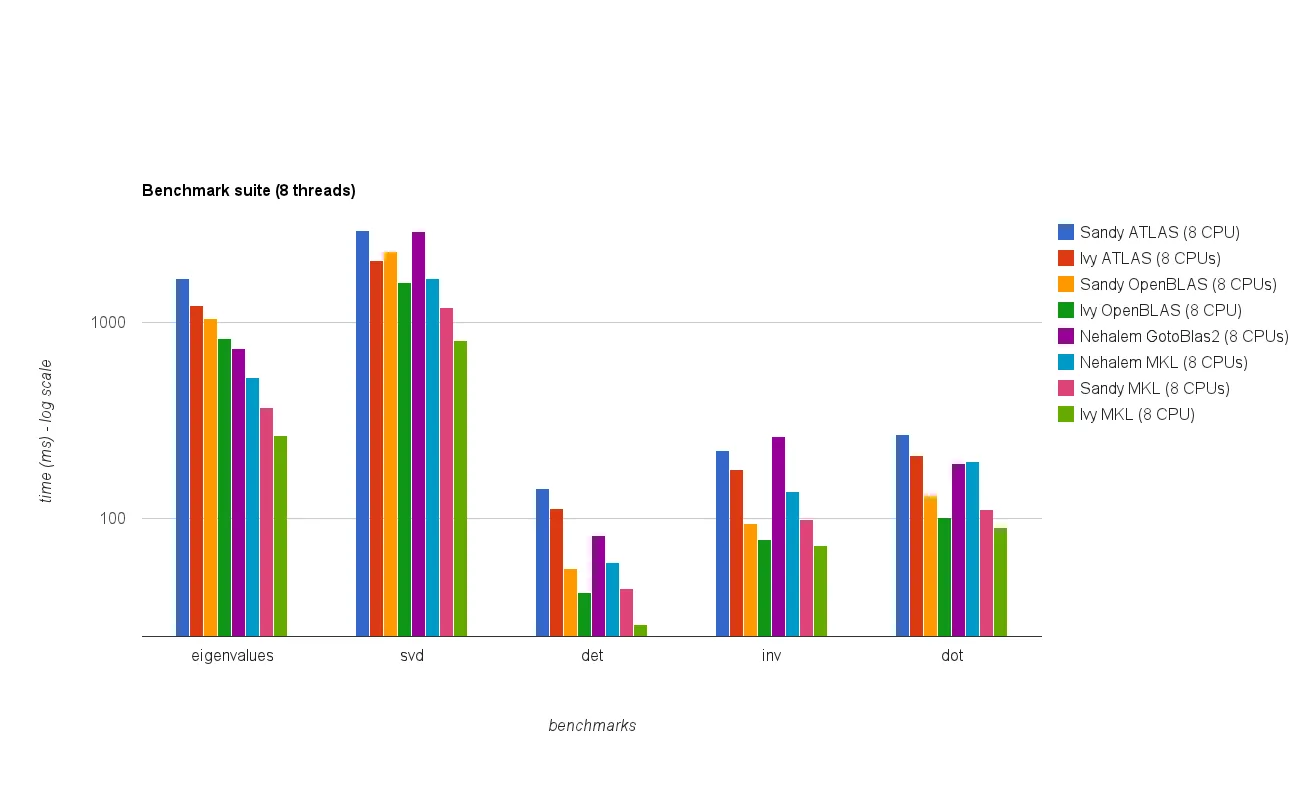
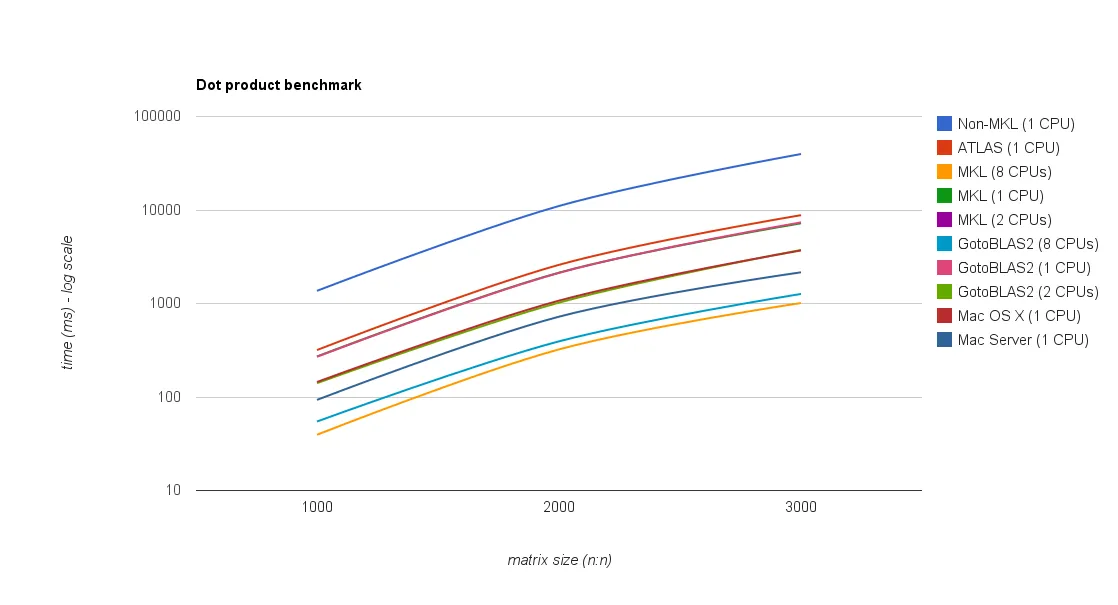
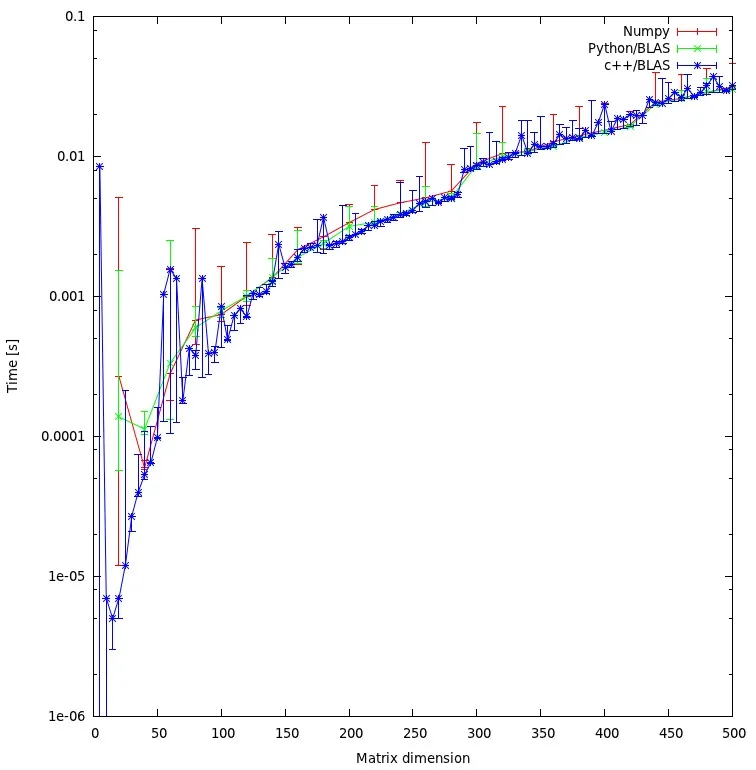
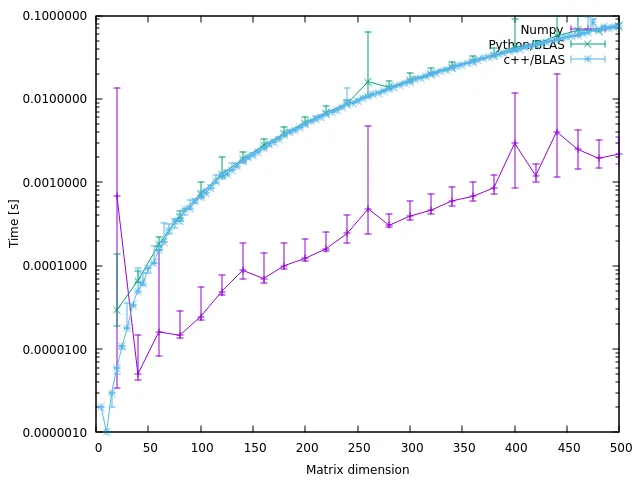
结果
下图显示了结果:
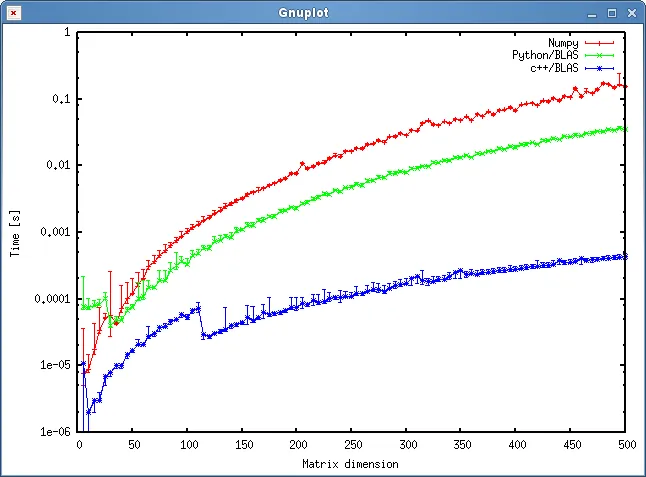
问题
- 您认为我的方法是否公平,是否可以避免一些不必要的开销?
- 您是否预计结果会显示C++和Python方法之间如此巨大的差异?两者都使用共享对象进行计算。
- 由于我更愿意在我的程序中使用Python,我该怎么做才能提高调用BLAS或LAPACK例程的性能?
下载
完整的基准测试可以从这里下载。(J.F. Sebastian使该链接成为可能^^)
![Matrix multiplication (sizes=[1000,2000,3000,5000,8000])](https://istack.dev59.com/ZU7u4.webp)
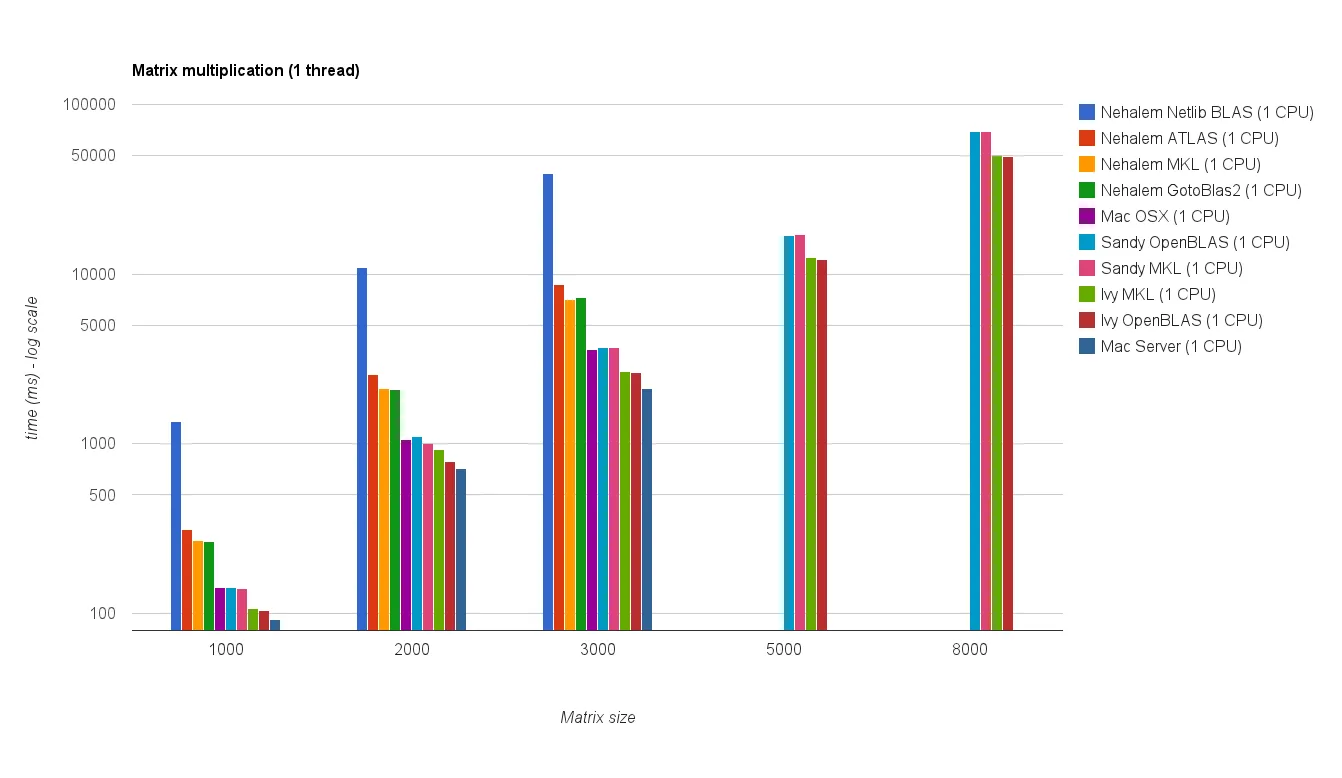
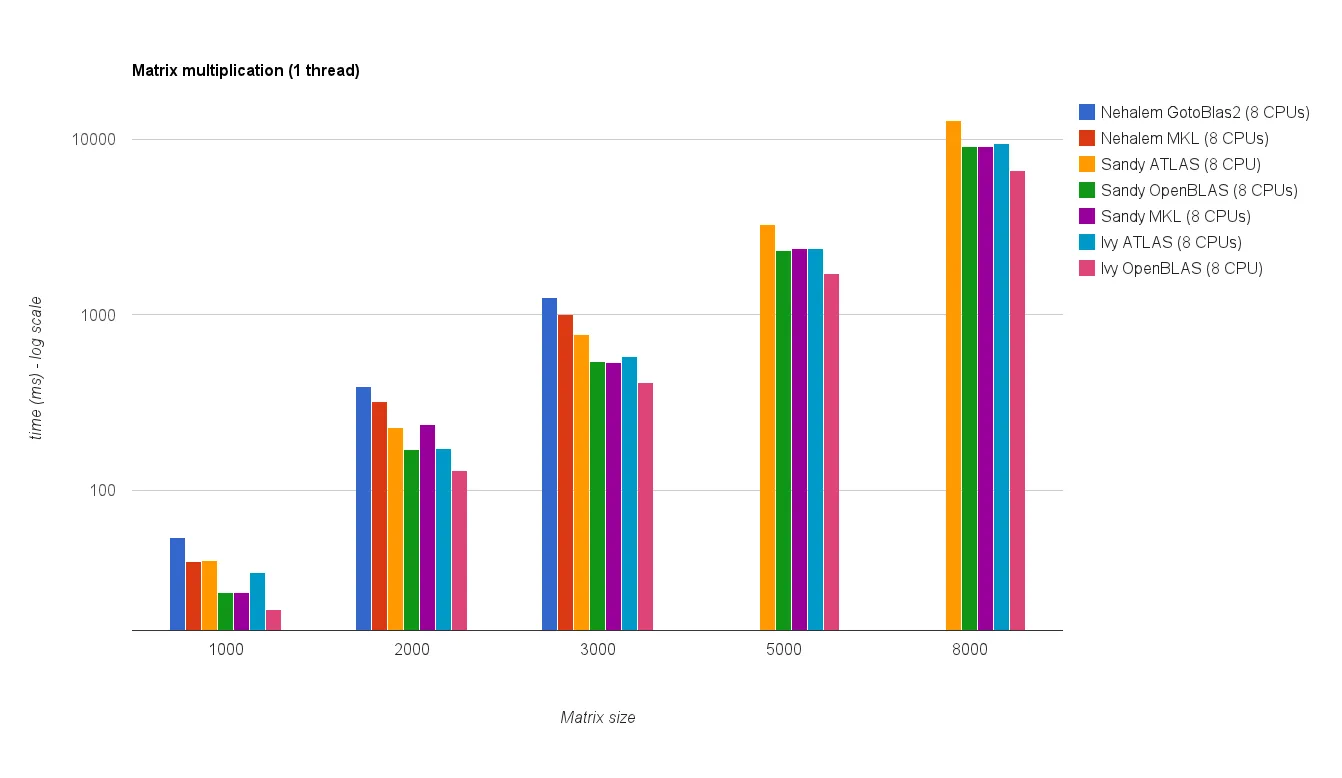
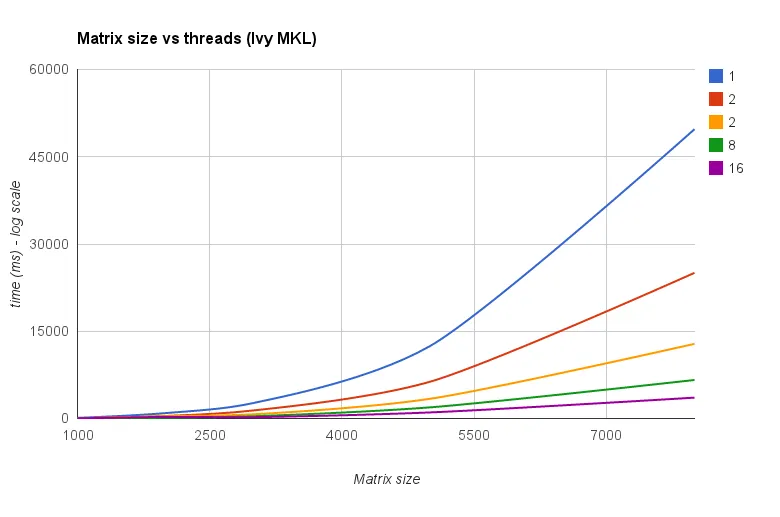
{kind=link}
r矩阵的内存分配是不公平的。我正在解决这个“问题”,并将发布新的结果。 - Woltan