我正试图在Python中实现大量的矩阵-矩阵乘法。最初,我认为NumPy会自动使用我的线程化BLAS库,因为我已经构建了它并针对这些库进行了优化。但是,当我查看top或其他一些东西时,似乎代码根本没有使用线程。
有什么想法是出了什么问题,或者我可以做些什么来轻松地使用BLAS性能呢?
我正试图在Python中实现大量的矩阵-矩阵乘法。最初,我认为NumPy会自动使用我的线程化BLAS库,因为我已经构建了它并针对这些库进行了优化。但是,当我查看top或其他一些东西时,似乎代码根本没有使用线程。
有什么想法是出了什么问题,或者我可以做些什么来轻松地使用BLAS性能呢?
我已经在另一个帖子中发布了这个问题,但我认为它更适合在这个帖子中:
我在我们的新HPC上重新运行了基准测试。硬件和软件堆栈都与原始答案中的设置不同。
我将结果放在google spreadsheet中(还包括原始答案的结果)。
我们的HPC有两个不同的节点,一个使用Intel Sandy Bridge CPU,另一个使用更新的Ivy Bridge CPU:
Sandy(MKL,OpenBLAS,ATLAS):
Ivy(MKL,OpenBLAS,ATLAS):
这个软件栈对于两个节点都是相同的。使用的不是GotoBLAS2,而是OpenBLAS,还有一个设置为8线程(硬编码)的多线程ATLAS BLAS。
基准代码与下面相同。但是对于新机器,我还运行了矩阵大小为5000和8000的基准测试。
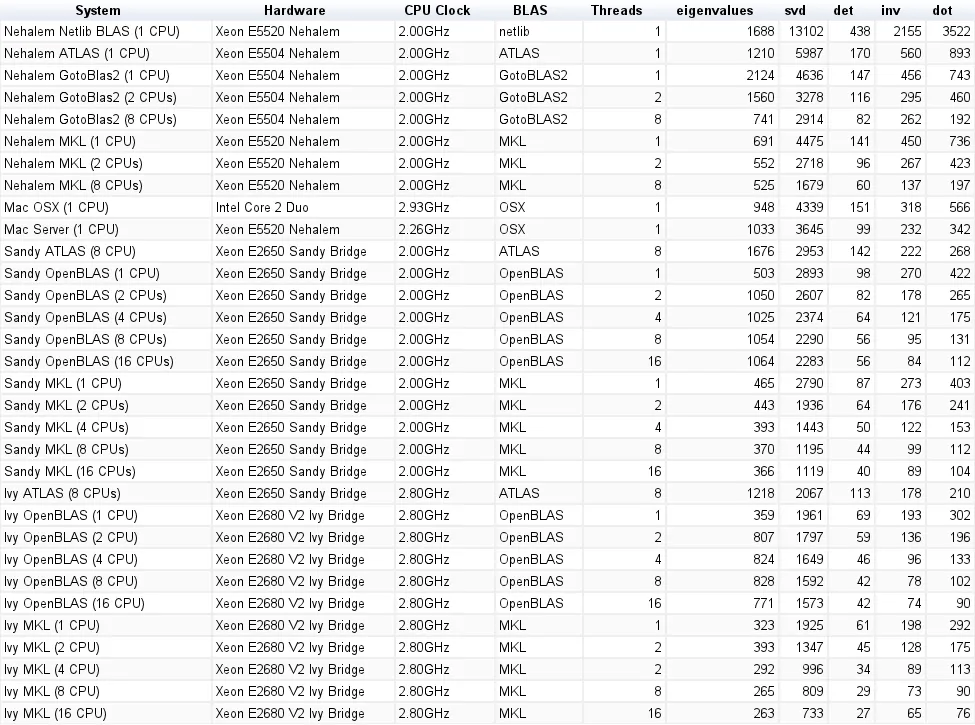
下表包括原始答案的基准测试结果(重命名为:MKL --> Nehalem MKL,Netlib Blas --> Nehalem Netlib BLAS等)
![Matrix multiplication (sizes=[1000,2000,3000,5000,8000])](https://istack.dev59.com/ZU7u4.webp)
单线程性能:
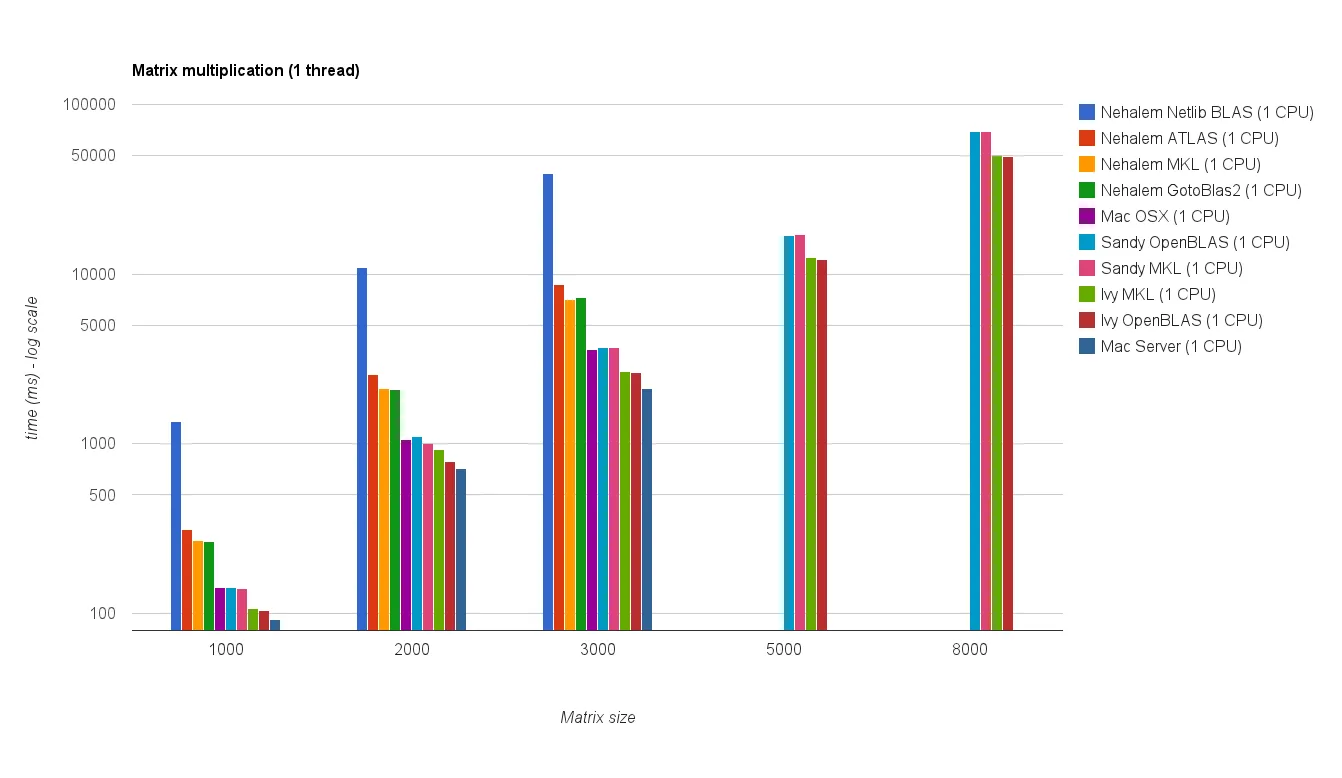
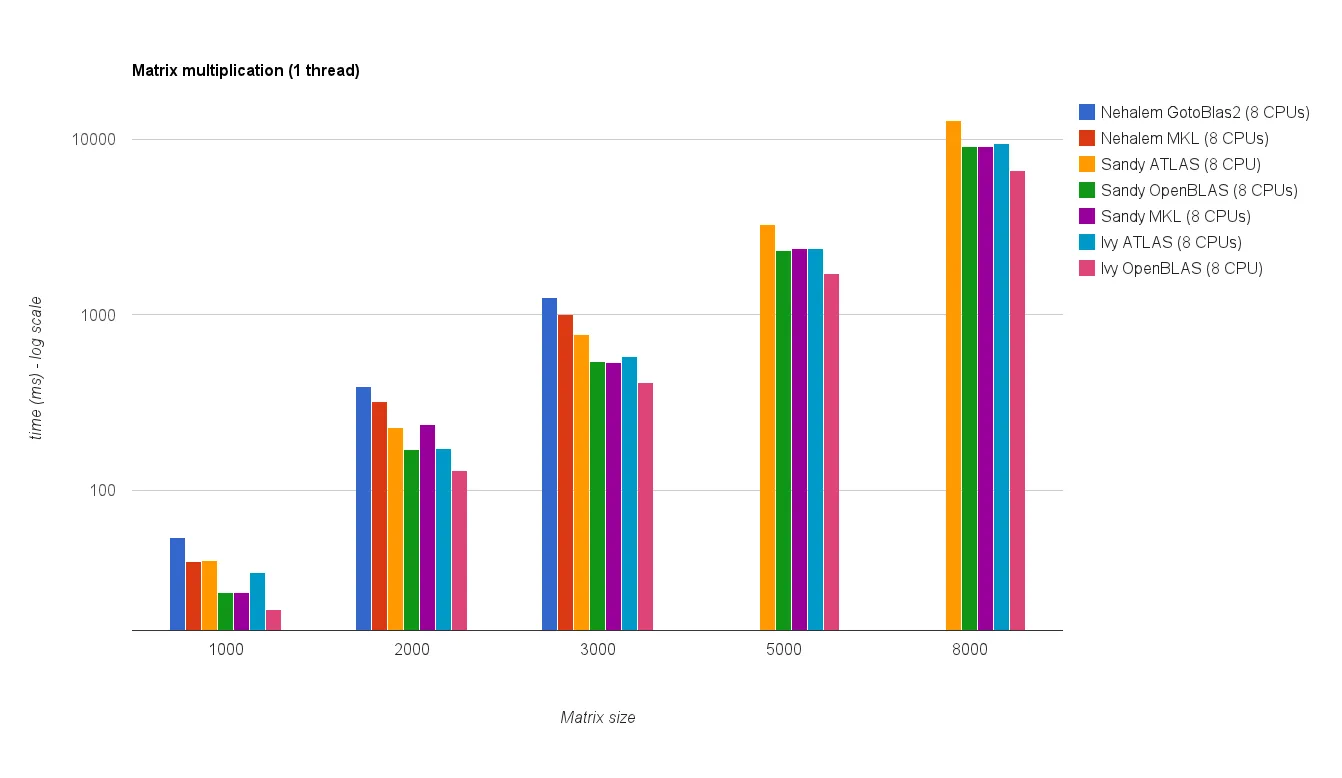
多线程性能(8个线程):
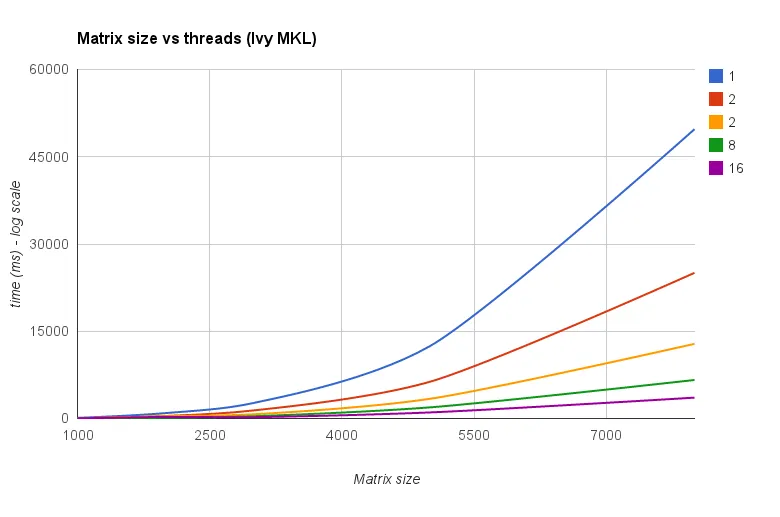
线程数 vs 矩阵大小(Ivy Bridge MKL):
单线程性能:
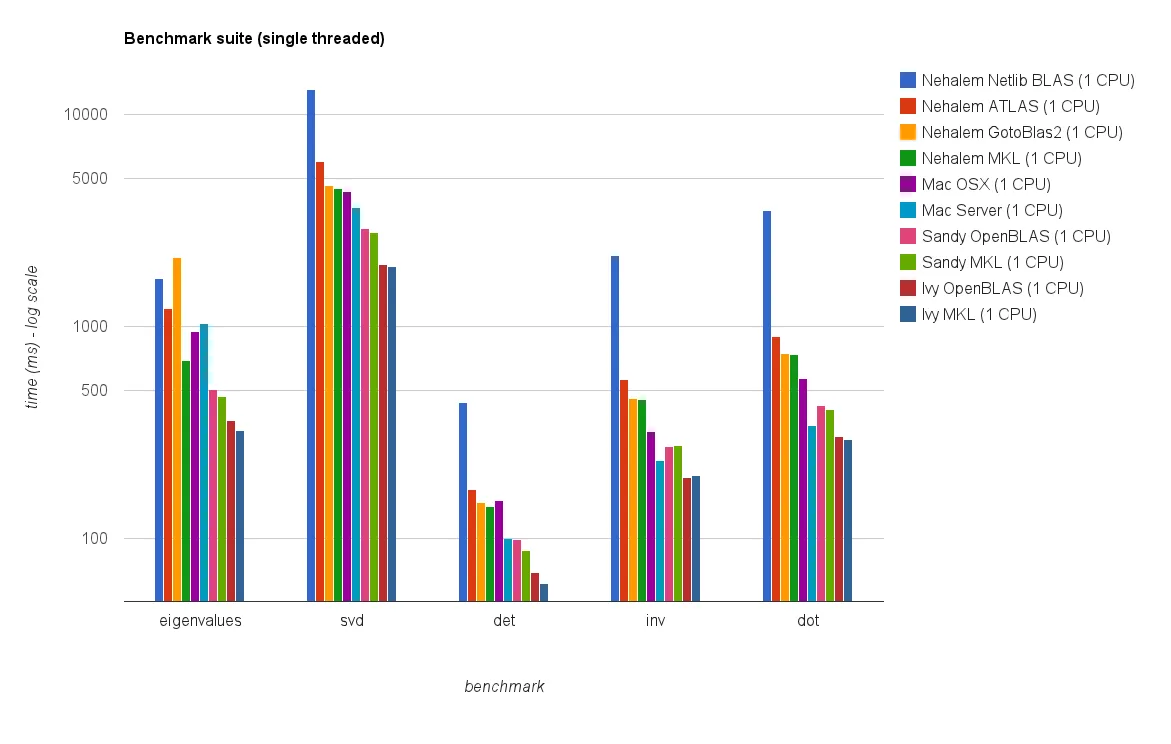
多线程(8个线程)性能:
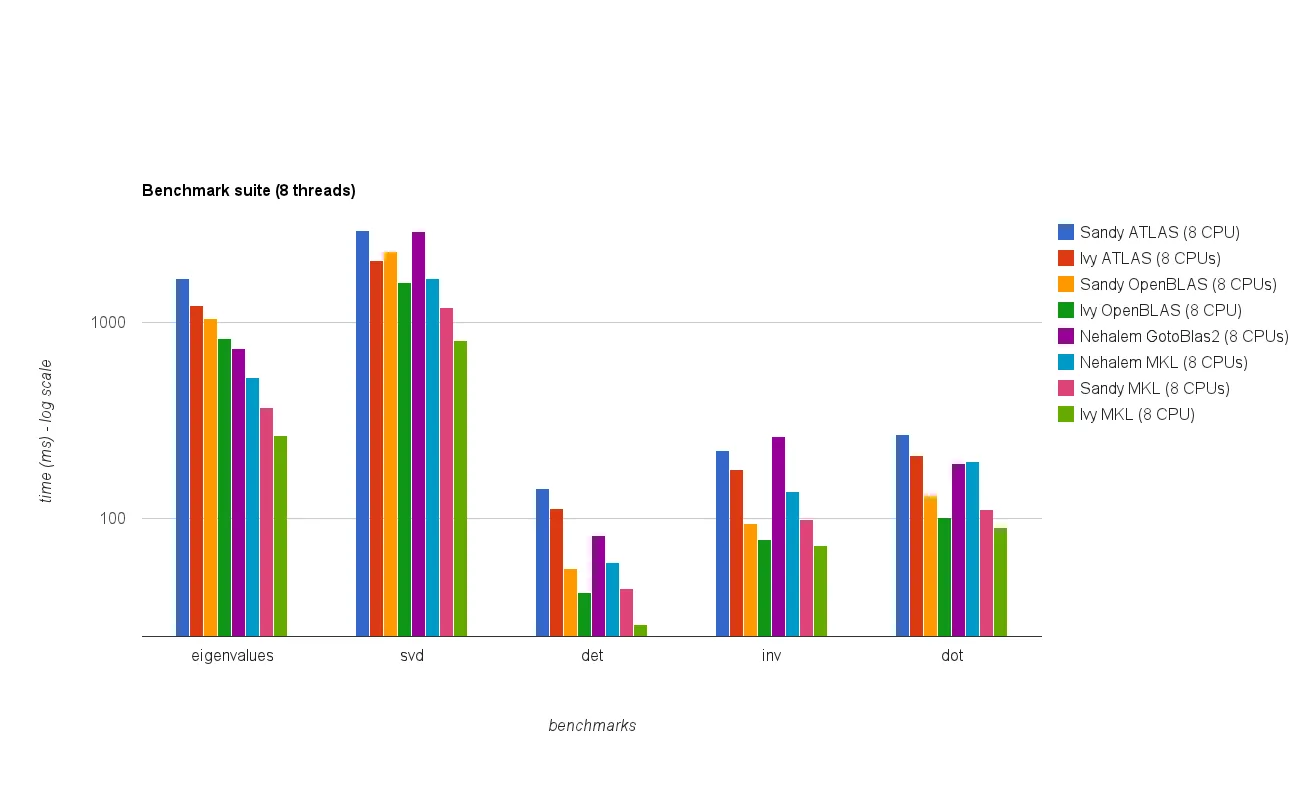
新的基准测试结果与原答案中的结果相似。 OpenBLAS 和 MKL 的表现相当,除了特征值测试。 在单线程模式下,OpenBLAS 的特征值测试表现只是合理的。 在多线程模式下,性能更差。
"矩阵大小 vs 线程图表" 也显示,尽管 MKL 和 OpenBLAS 通常随着核心/线程数的增加而扩展得很好,但这取决于矩阵的大小。对于小矩阵,添加更多核心不会显著提高性能。
从Sandy Bridge到Ivy Bridge还有大约30%的性能提升,这可能是由于更高的时钟速率(+0.8 GHz)和/或更好的架构。
不久前,我不得不优化一些使用numpy和BLAS编写的线性代数计算/算法的python代码,因此我对不同的numpy/BLAS配置进行了基准测试。
具体而言,我测试了:
我运行了两个不同的基准测试:
以下是我的结果:
Linux(MKL、ATLAS、No-MKL、GotoBlas2):
Mac Book Pro (Accelerate Framework):
Mac Server (Accelerate Framework):
代码:
import numpy as np
a = np.random.random_sample((size,size))
b = np.random.random_sample((size,size))
%timeit np.dot(a,b)
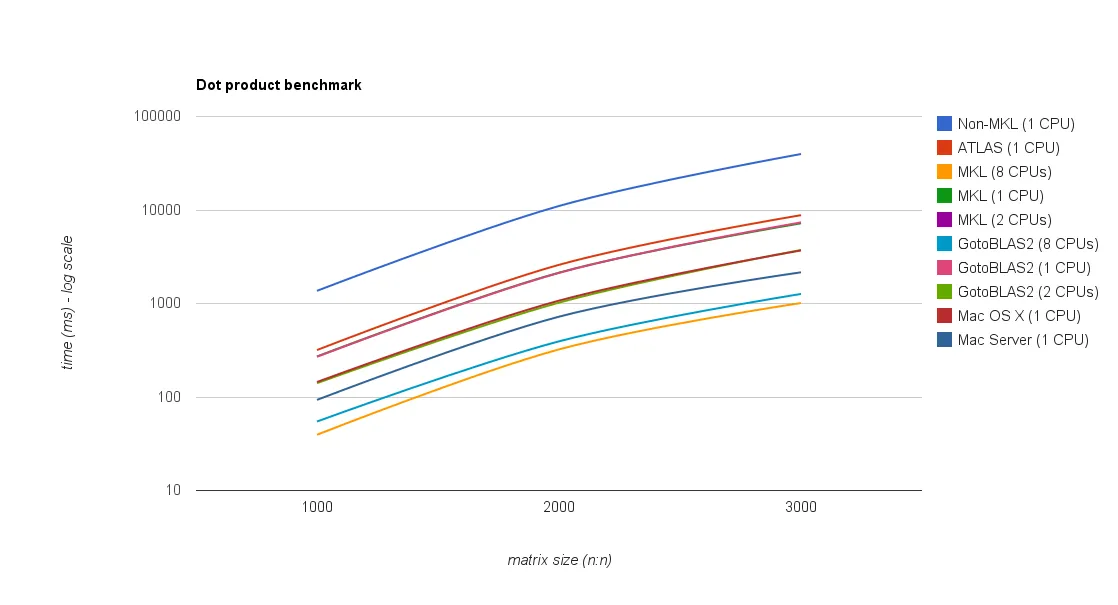
结果:
系统 | 大小 = 1000 | 大小 = 2000 | 大小 = 3000 | netlib BLAS | 1350 毫秒 | 10900 毫秒 | 39200 毫秒 | ATLAS (1 CPU) | 314 毫秒 | 2560 毫秒 | 8700 毫秒 | MKL (1 CPUs) | 268 毫秒 | 2110 毫秒 | 7120 毫秒 | MKL (2 CPUs) | - | - | 3660 毫秒 | MKL (8 CPUs) | 39 毫秒 | 319 毫秒 | 1000 毫秒 | GotoBlas2 (1 CPU) | 266 毫秒 | 2100 毫秒 | 7280 毫秒 | GotoBlas2 (2 CPUs)| 139 毫秒 | 1009 毫秒 | 3690 毫秒 | GotoBlas2 (8 CPUs)| 54 毫秒 | 389 毫秒 | 1250 毫秒 | Mac OS X (1 CPU) | 143 毫秒 | 1060 毫秒 | 3605 毫秒 | Mac Server (1 CPU)| 92 毫秒 | 714 毫秒 | 2130 毫秒 |
代码:
有关基准测试套件的更多信息,请参见此处。
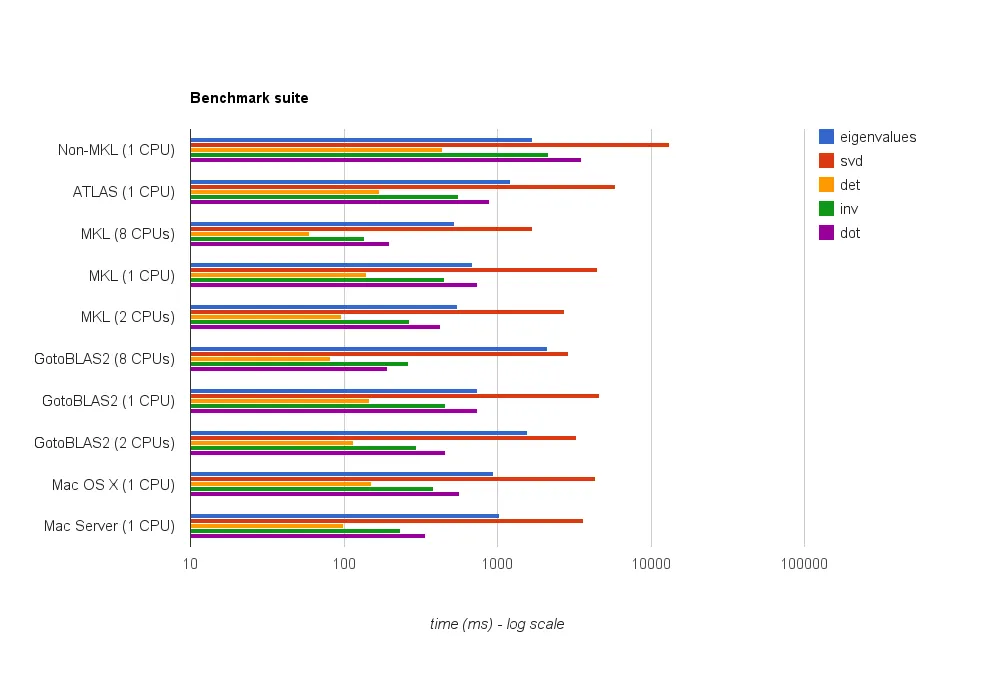
结果:
系统 | 特征值分解时间 | SVD时间 | 行列式时间 | 逆矩阵时间 | 点乘时间 | netlib BLAS | 1688毫秒 | 13102毫秒 | 438毫秒 | 2155毫秒 | 3522毫秒 | ATLAS (1 CPU) | 1210毫秒 | 5897毫秒 | 170毫秒 | 560毫秒 | 893毫秒 | MKL (1 CPUs) | 691毫秒 | 4475毫秒 | 141毫秒 | 450毫秒 | 736毫秒 | MKL (2 CPUs) | 552毫秒 | 2718毫秒 | 96毫秒 | 267毫秒 | 423毫秒 | MKL (8 CPUs) | 525毫秒 | 1679毫秒 | 60毫秒 | 137毫秒 | 197毫秒 | GotoBlas2 (1 CPU) | 2124毫秒 | 4636毫秒 | 147毫秒 | 456毫秒 | 743毫秒 | GotoBlas2 (2 CPUs)| 1560毫秒 | 3278毫秒 | 116毫秒 | 295毫秒 | 460毫秒 | GotoBlas2 (8 CPUs)| 741毫秒 | 2914毫秒 | 82毫秒 | 262毫秒 | 192毫秒 | Mac OS X (1 CPU) | 948毫秒 | 4339毫秒 | 151毫秒 | 318毫秒 | 566毫秒 | Mac Server (1 CPU)| 1033毫秒 | 3645毫秒 | 99毫秒 | 232毫秒 | 342毫秒 |
安装MKL需要安装完整的Intel编译器套件,这相当简单。但是由于一些bug/问题,配置和编译支持MKL的numpy有点麻烦。
GotoBlas2是一个小型软件包,可以轻松地编译为共享库。然而,由于一个bug,您必须在构建后重新创建共享库才能将其与numpy一起使用。
此外,为多个目标平台构建它出了一些问题。因此,我不得不为每个我想要拥有优化的libgoto2.so文件的平台创建一个.so文件。
如果您从Ubuntu存储库中安装numpy,则会自动安装和配置numpy以使用ATLAS。从源代码安装ATLAS可能需要一些时间,并且需要一些额外的步骤(fortran等)。
如果您在带有Fink或Mac Ports的Mac OS X机器上安装numpy,则它将配置numpy以使用ATLAS或Apple的Accelerate Framework之一。 您可以通过运行ldd命令查看numpy.core._dotblas文件或调用numpy.show_config()来检查。
MKL表现最佳,紧随其后的是GotoBlas2。
在特征值测试中,GotoBlas2的表现比预期的要差得多。不确定为什么会出现这种情况。
苹果的加速框架Accelerate Framework表现非常好,尤其是在单线程模式下(与其他BLAS实现相比)。
GotoBlas2和MKL都能很好地随着线程数量的增加而扩展。因此,如果您需要处理大型矩阵,则在多个线程上运行它将有很大帮助。
无论如何,不要使用默认的netlib blas实现,因为它对于任何严肃的计算工作来说都太慢了。
在我们的集群上,我还安装了AMD的ACML,性能与MKL和GotoBlas2相似。但我没有任何数字数据。
我个人建议使用GotoBlas2,因为它更容易安装,而且是免费的。
如果您想使用C++/C进行编码,还应该查看Eigen3,它在某些cases中表现优于MKL/GotoBlas2,而且使用起来也非常简单。
_dotblas.so文件上执行ldd命令。它将显示该so文件链接到哪些库(在MKL的情况下是mkl so等)。 - Ümit不是所有的NumPy都使用BLAS,只有一些函数 -- 具体来说是dot()、vdot()、innerproduct()和numpy.linalg模块中的几个函数。此外,请注意,在处理大数组时,许多NumPy操作受到存储器带宽的限制,因此优化实现不太可能带来任何改进。如果您受到存储器带宽的限制,则多线程是否可以提供更好的性能严重取决于您的硬件。
numpy.dot(),这也是内部实现的方式。但是如果不知道你具体在做什么,就很难给出进一步的建议。也许你想开一个新问题来询问。 - Sven Marnach由于矩阵乘法受到内存限制,因此在相同的内存层次结构上添加额外的核心并不能带来太多好处。当然,如果您在切换到Fortran实现时看到了实质性的加速,则我可能是错误的。
我理解的是,对于这些问题,适当的缓存远比计算能力重要。BLAS可能会为您完成这项工作。
对于简单的测试,您可以尝试安装Enthought's python发行版进行比较。它们链接到英特尔的Math Kernel Library,我相信该库可以利用多个可用的核心。
你听说过MAGMA吗? GPU和多核架构上的矩阵代数 http://icl.cs.utk.edu/magma/
MAGMA项目旨在开发一种类似于LAPACK的密集线性代数库,用于异构/混合体系结构,从当前的“多核+GPU”系统开始。