我使用pandas.cut()将连续变量离散化为一定范围,然后按结果进行分组。
经过很多痛骂,因为我找不到问题出在哪里,我学会了如果我不提供自定义标签给cut()函数,而是依赖于默认值,那么输出就无法导出到Excel。如果我尝试这样做:
经过很多痛骂,因为我找不到问题出在哪里,我学会了如果我不提供自定义标签给cut()函数,而是依赖于默认值,那么输出就无法导出到Excel。如果我尝试这样做:
import pandas as pd
import numpy as np
writer = pd.ExcelWriter('test.xlsx')
wk = writer.book.add_worksheet('Test')
df= df= pd.DataFrame(np.random.randint(1,10,(10000,5)), columns=['a','b','c','d','e'])
df['range'] = pd.cut( df['a'],[-np.inf,3,8,np.inf] )
grouped=df.groupby('range').sum()
grouped.to_excel(writer, 'Export')
writer.close()
我得到:
raise TypeError("Unsupported type %s in write()" % type(token))
TypeError: Unsupported type <class 'pandas._libs.interval.Interval'> in write()
which it took me a while to decypher.
如果我分配标签:
df['range'] = pd.cut( df['a'],[-np.inf,3,8,np.inf], labels =['<3','3-8','>8'] )
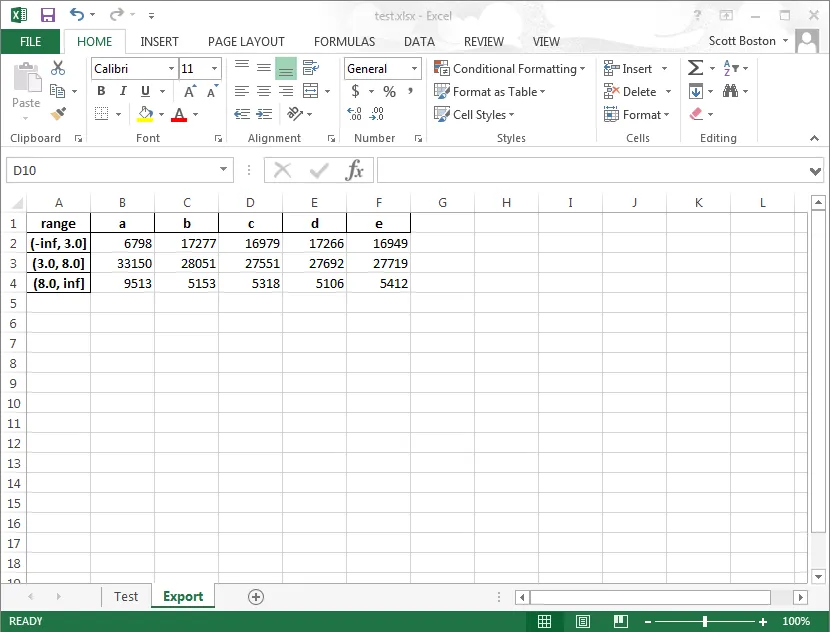
df['range'] = pd.cut(df['a'],[-np.inf,3,8,np.inf], labels =['<3','3-8','>8']).astype(str)- Paul Hlabels关键字参数,据我所知。 - Paul H