我有一个关于使用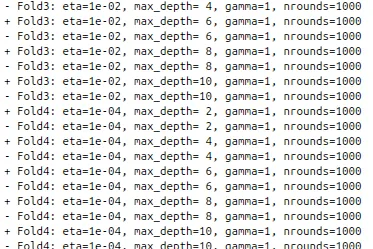 我的问题是为什么每个超参数配置会有多行,并且输出中的
我的问题是为什么每个超参数配置会有多行,并且输出中的
下面是一个可以产生上述输出的示例代码(从这里随机选取):
train函数在caret中进行交叉验证超参数搜索的基本问题。在运行时,它会产生以下输出:
我的问题是为什么每个超参数配置会有多行,并且输出中的+和-代表什么?下面是一个可以产生上述输出的示例代码(从这里随机选取):
library(caret)
library(datasets)
data(mtcars)
split = createDataPartition(y = mtcars$mpg, p = 0.6, list = FALSE)
dev = mtcars[split,]
val = mtcars[-split,]
ctrl = trainControl(method = "cv",number = 10, verbose = TRUE)
lmCVFit = train(mpg ~ ., data = mtcars, method = "lm", trControl = ctrl, metric="Rsquared")
summary(lmCVFit)
verbose = TRUE调用train的输出都是相同的。添加了一些示例代码。 - undefined