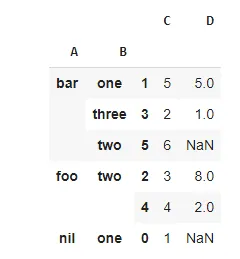
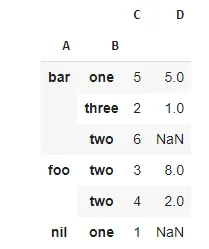
我已经花了数小时在各处浏览,试图从pandas中的数据框创建多索引。这是我拥有的数据框(发布Excel表格模拟。我确实在pandas数据框中拥有此数据):
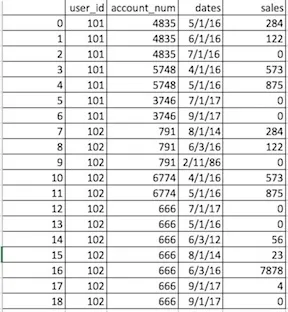
这就是我想要的:
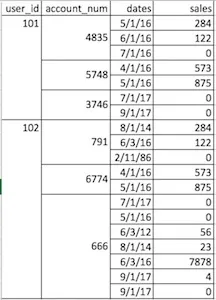
我已经尝试过
newmulti = currentDataFrame.set_index(['user_id','account_num'])
但它返回的是数据框,而不是多级索引。此外,我无法弄清楚如何将'user_id'设置为0级,'account_num'设置为1级。我认为这应该很简单,但我已经阅读了很多帖子、教程等,仍然无法弄清楚。部分原因是因为我是一个非常视觉化的人,而大多数帖子都不是。请帮帮我!