我开始使用scikit-garden软件包中的分位数随机森林(QRFs)。以前,我使用sklearn.ensemble中的RandomForestRegresser创建常规随机森林。
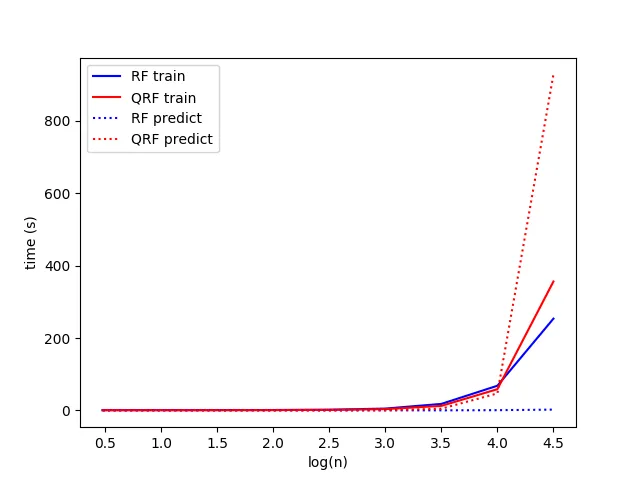
看起来QRF的速度与小数据集大小的常规RF相当,但随着数据量的增加,QRF在进行预测时比RF慢得多。
这是正常现象吗?如果是,能否请有经验的人解释一下为什么需要如此长的时间来进行这些预测,并提出任何建议,以便我能够更及时地获取分位数预测结果。
请参见下面的玩具示例,其中我测试了各种数据集大小的训练和预测时间。
import matplotlib as mpl
mpl.use('Agg')
from sklearn.ensemble import RandomForestRegressor
from skgarden import RandomForestQuantileRegressor
from sklearn.model_selection import train_test_split
import numpy as np
import time
import matplotlib.pyplot as plt
log_ns = np.arange(0.5, 5, 0.5) # number of observations (log10)
ns = (10 ** (log_ns)).astype(int)
print(ns)
m = 14 # number of covariates
train_rf = []
train_qrf = []
pred_rf = []
pred_qrf = []
for n in ns:
# create dataset
print('n = {}'.format(n))
print('m = {}'.format(m))
rndms = np.random.normal(size=n)
X = np.random.uniform(size=[n,m])
betas = np.random.uniform(size=m)
y = 3 + np.sum(betas[None,:] * X, axis=1) + rndms
# split test/train
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# random forest
rf = RandomForestRegressor(n_estimators=1000, random_state=0)
st = time.time()
rf.fit(X_train, y_train)
en = time.time()
print('Fit time RF = {} secs'.format(en - st))
train_rf.append(en - st)
# quantile random forest
qrf = RandomForestQuantileRegressor(random_state=0, min_samples_split=10, n_estimators=1000)
qrf.set_params(max_features = X.shape[1] // 3)
st = time.time()
qrf.fit(X_train, y_train)
en = time.time()
print('Fit time QRF = {} secs'.format(en - st))
train_qrf.append(en - st)
# predictions
st = time.time()
preds_rf = rf.predict(X_test)
en = time.time()
print('Prediction time RF = {}'.format(en - st))
pred_rf.append(en - st)
st = time.time()
preds_qrf = qrf.predict(X_test, quantile=50)
en = time.time()
print('Prediction time QRF = {}'.format(en - st))
pred_qrf.append(en - st)
fig, ax = plt.subplots()
ax.plot(np.log10(ns), train_rf, label='RF train', color='blue')
ax.plot(np.log10(ns), train_qrf, label='QRF train', color='red')
ax.plot(np.log10(ns), pred_rf, label='RF predict', color='blue', linestyle=':')
ax.plot(np.log10(ns), pred_qrf, label='QRF predict', color='red', linestyle =':')
ax.legend()
ax.set_xlabel('log(n)')
ax.set_ylabel('time (s)')
fig.savefig('time_comparison.png')
以下是输出结果: RF和QRF训练及预测的时间比较
{kind=link}