以下是我的数据表,来自我的代码输出:
通常,当我尝试去除重复项时,我会使用
| columnA|ColumnB|ColumnC|
| ------ | ----- | ------|
| 12 | 8 | 1.34 |
| 8 | 12 | 1.34 |
| 1 | 7 | 0.25 |
我想要去重并只保留一个
| columnA|ColumnB|ColumnC|
| ------ | ----- | ------|
| 12 | 8 | 1.34 |
| 1 | 7 | 0.25 |
通常,当我尝试去除重复项时,我会使用
.drop_duplicates(subset=)方法。但是这次,我想要删除相同的一对,例如:我想要删除 (columnA,columnB)==(columnB,columnA)。我做了一些调查,我发现有人使用set((a,b) if a<=b else (b,a) for a,b in pairs)来删除相同的列表对。但我不知道如何在pandas数据框上使用此方法。请帮忙解决,提前致谢!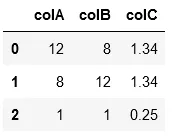
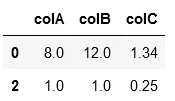
frozenset。好答案,已点赞! - Code Different