假设我有一个如下的表格
A B C B
0 0 1 2 3
1 4 5 6 7
我想删除B列。我尝试使用drop_duplicates,但它似乎只基于重复的数据而不是标题工作。
希望有人知道如何做到这一点。
假设我有一个如下的表格
A B C B
0 0 1 2 3
1 4 5 6 7
我想删除B列。我尝试使用drop_duplicates,但它似乎只基于重复的数据而不是标题工作。
希望有人知道如何做到这一点。
使用 Index.duplicated 方法与 loc 或 iloc 以及布尔索引一起使用:
print (~df.columns.duplicated())
[ True True True False]
df = df.loc[:, ~df.columns.duplicated()]
print (df)
A B C
0 0 1 2
1 4 5 6
df = df.iloc[:, ~df.columns.duplicated()]
print (df)
A B C
0 0 1 2
1 4 5 6
时间:
np.random.seed(123)
cols = ['A','B','C','B']
#[1000 rows x 30 columns]
df = pd.DataFrame(np.random.randint(10, size=(1000,30)),columns = np.random.choice(cols, 30))
print (df)
In [115]: %timeit (df.groupby(level=0, axis=1).first())
1000 loops, best of 3: 1.48 ms per loop
In [116]: %timeit (df.groupby(level=0, axis=1).mean())
1000 loops, best of 3: 1.58 ms per loop
In [117]: %timeit (df.iloc[:, ~df.columns.duplicated()])
1000 loops, best of 3: 338 µs per loop
In [118]: %timeit (df.loc[:, ~df.columns.duplicated()])
1000 loops, best of 3: 346 µs per loop
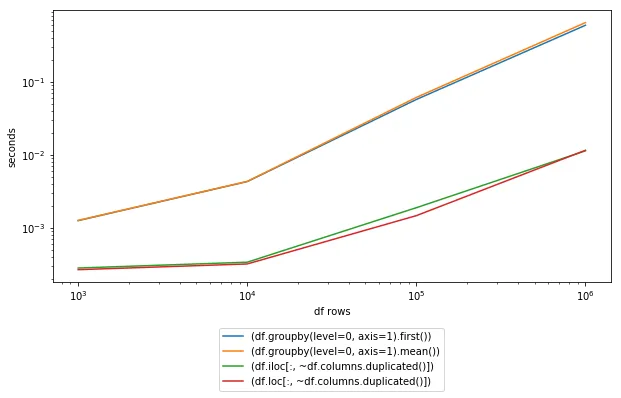
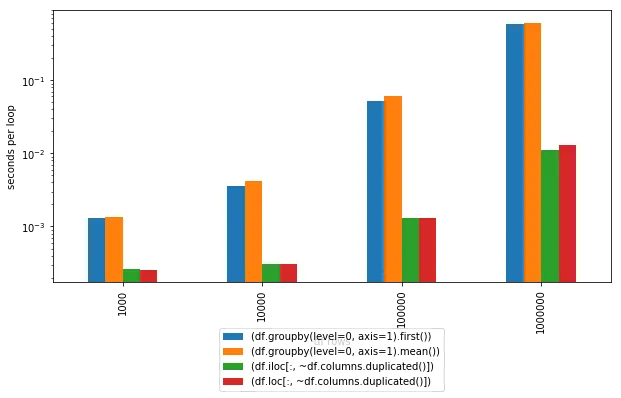
groupby 进行分组。axis=1 和 level=0 参数来指定我们正在按列进行分组。然后使用 first 方法来获取由唯一列名定义的每个组中的第一列。df.groupby(level=0, axis=1).first()
A B C
0 0 1 2
1 4 5 6
last。df.groupby(level=0, axis=1).last()
A B C
0 0 3 2
1 4 7 6
平均值
df.groupby(level=0, axis=1).mean()
A B C
0 0 2 2
1 4 6 6