追加字符串到一个字符串变量中的最佳方式是使用+ 或 +=。这是因为它既易读又快速。它们的速度也是一样的,你选择哪个取决于个人口味,后者是最常见的。以下是使用 timeit 模块计时的结果:
a = a + b:
0.11338996887207031
a += b:
0.11040496826171875
然而,那些建议使用列表并将其附加到字符串再连接这些列表的人之所以这样做,是因为将字符串附加到列表中可能比将字符串扩展快得多。在某些情况下,这确实是正确的。例如,在这里,我们对一个包含一百万个单字符字符串的字符串和列表进行了一百万次附加操作:
a += b:
0.10780501365661621
a.append(b):
0.1123361587524414
好的,事实证明,即使生成的字符串长度为一百万个字符,使用追加仍然更快。
现在让我们尝试将一个一千个字符长的字符串追加一万次:
a += b:
0.41823482513427734
a.append(b):
0.010656118392944336
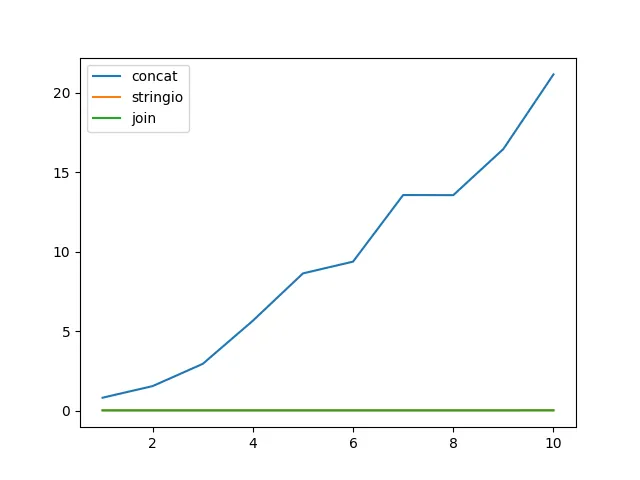
因此,最终字符串大约有100MB长。这种方法很慢,使用列表添加数据的速度更快。这个时间不包括最后的 a.join()。那么这需要多长时间?
a.join(a):
0.43739795684814453
糟糕。结果发现即使在这种情况下,使用append/join仍然较慢。
那么这个建议是从哪里来的?Python 2吗?
a += b:
0.165287017822
a.append(b):
0.0132720470428
a.join(a):
0.114929914474
如果你正在使用非常长的字符串(通常不会有100MB内存的字符串),那么在那种情况下,使用追加/连接操作可能会稍微快一些。但是真正的关键在于Python 2.3。我甚至不会向你展示时间,因为它太慢了,还没有完成。这些测试突然需要花费几分钟的时间。除了追加/连接之外,在后来的版本中都和以前一样快。
没错,在Python语言的早期,字符串拼接非常缓慢。但在2.4版之后,它不再缓慢了(或者至少在Python 2.4.7中如此),因此在2008年时,当Python 2.3停止更新时,使用追加/连接的建议已经过时了,你应该停止使用这种方法。 :-)
(更新: 后来我仔细测试后发现,在Python 2.3中对于两个字符串使用+和+=也更快。使用''.join()进行连接的建议可能是一个误解)
然而,这只适用于CPython解释器。其他实现可能会有其他问题。这也是为什么过早优化是万恶之源的又一个原因。除非你先进行度量,否则不要使用一个被认为是“更快”的技术。
因此,"最好"的字符串拼接版本是使用+或+=。如果这对你来说太慢了,那就尝试其他方法。
那么为什么我在我的代码中经常使用追加/连接呢?因为有时候它实际上更容易理解。特别是当你希望将要拼接的内容用空格、逗号或换行符隔开时。