我在看这个Web Audio API演示, 它是这本不错的书的一部分
如果你看一下演示,fft峰值会平滑地下降。我试图使用minim库在Java模式下做同样的事情。我查看了如何使用doFFTAnalysis()方法在Web音频API中完成此操作,并尝试使用minim复制它。我还尝试移植复数类型的abs()函数的工作方式:
/ 26.2.7/3 abs(__z): Returns the magnitude of __z.
00565 template<typename _Tp>
00566 inline _Tp
00567 __complex_abs(const complex<_Tp>& __z)
00568 {
00569 _Tp __x = __z.real();
00570 _Tp __y = __z.imag();
00571 const _Tp __s = std::max(abs(__x), abs(__y));
00572 if (__s == _Tp()) // well ...
00573 return __s;
00574 __x /= __s;
00575 __y /= __s;
00576 return __s * sqrt(__x * __x + __y * __y);
00577 }
00578
我目前正在使用 Processing(Java 框架/库)进行快速原型开发。我的代码看起来像这样:
import ddf.minim.*;
import ddf.minim.analysis.*;
private int blockSize = 512;
private Minim minim;
private AudioInput in;
private FFT mfft;
private float[] time = new float[blockSize];//time domain
private float[] real = new float[blockSize];
private float[] imag = new float[blockSize];
private float[] freq = new float[blockSize];//smoothed freq. domain
public void setup() {
minim = new Minim(this);
in = minim.getLineIn(Minim.STEREO, blockSize);
mfft = new FFT( in.bufferSize(), in.sampleRate() );
}
public void draw() {
background(255);
for (int i = 0; i < blockSize; i++) time[i] = in.left.get(i);
mfft.forward( time);
real = mfft.getSpectrumReal();
imag = mfft.getSpectrumImaginary();
final float magnitudeScale = 1.0 / mfft.specSize();
final float k = (float)mouseX/width;
for (int i = 0; i < blockSize; i++)
{
float creal = real[i];
float cimag = imag[i];
float s = Math.max(creal,cimag);
creal /= s;
cimag /= s;
float absComplex = (float)(s * Math.sqrt(creal*creal + cimag*cimag));
float scalarMagnitude = absComplex * magnitudeScale;
freq[i] = (k * mfft.getBand(i) + (1 - k) * scalarMagnitude);
line( i, height, i, height - freq[i]*8 );
}
fill(0);
text("smoothing: " + k,10,10);
}
我的代码没有出现错误,这很好,但是我没有得到期望的行为,这很糟糕。 当平滑(k)接近1时,我希望峰值下降得更慢,但据我所知,我的代码只缩放了频段。
不幸的是,数学和声音不是我的强项,所以我是在摸索着。如何才能复制Web Audio API演示中的不错可视化效果呢?
我想说这可能与编程语言无关,但例如使用JavaScript就行不通 :).不过,我愿意尝试任何其他可以进行FFT分析的Java库。
更新
我已经有了平滑的简单解决方案(如果当前fft频段不高,则连续减小每个先前fft频段的值):
import ddf.minim.analysis.*;
import ddf.minim.*;
Minim minim;
AudioInput in;
FFT fft;
float smoothing = 0;
float[] fftReal;
float[] fftImag;
float[] fftSmooth;
int specSize;
void setup(){
size(640, 360, P3D);
minim = new Minim(this);
in = minim.getLineIn(Minim.STEREO, 512);
fft = new FFT(in.bufferSize(), in.sampleRate());
specSize = fft.specSize();
fftSmooth = new float[specSize];
fftReal = new float[specSize];
colorMode(HSB,specSize,100,100);
}
void draw(){
background(0);
stroke(255);
fft.forward( in.left);
fftReal = fft.getSpectrumReal();
fftImag = fft.getSpectrumImaginary();
for(int i = 0; i < specSize; i++)
{
float band = fft.getBand(i);
fftSmooth[i] *= smoothing;
if(fftSmooth[i] < band) fftSmooth[i] = band;
stroke(i,100,50);
line( i, height, i, height - fftSmooth[i]*8 );
stroke(i,100,100);
line( i, height, i, height - band*8 );
}
text("smoothing: " + (int)(smoothing*100),10,10);
}
void keyPressed(){
float inc = 0.01;
if(keyCode == UP && smoothing < 1-inc) smoothing += inc;
if(keyCode == DOWN && smoothing > inc) smoothing -= inc;
}

褪色的图表是平滑的,完全饱和的是实时的。
然而,与Web音频API演示相比,我仍然缺少一些东西:
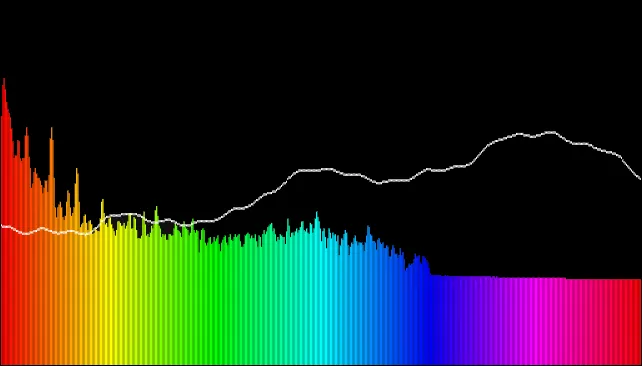
我试图阅读有关RealtimeAnalyser类如何为WebAudioAPI执行此操作的更多信息,但似乎FFTFrame类的
doFFT方法可能执行对数缩放。我还没有弄清楚doFFT的工作原理。如何使用对数比例尺缩放原始FFT图形以考虑感知?我的目标是做出一个看起来不错的可视化效果,我猜我需要:
- 平滑值,否则元素将动画过快/抖动 - 缩放FFT bins/bands以获得更好的中高频数据 - 将FFT值映射到视觉元素(找到最大值/边界)
你有什么提示可以帮助我实现这一点吗?
更新2
我猜测这部分是在Web音频API中实现平滑和缩放的: // 将输入正弦波归一化为0dBfs,以便其注册为0dBfs(撤销FFT缩放因子)。 const double magnitudeScale = 1.0 / DefaultFFTSize;
// A value of 0 does no averaging with the previous result. Larger values produce slower, but smoother changes.
double k = m_smoothingTimeConstant;
k = max(0.0, k);
k = min(1.0, k);
// Convert the analysis data from complex to magnitude and average with the previous result.
float* destination = magnitudeBuffer().data();
size_t n = magnitudeBuffer().size();
for (size_t i = 0; i < n; ++i) {
Complex c(realP[i], imagP[i]);
double scalarMagnitude = abs(c) * magnitudeScale;
destination[i] = float(k * destination[i] + (1 - k) * scalarMagnitude);
}
似乎缩放是通过取复杂值的绝对值来完成的。这篇文章指向同一个方向。我尝试使用Minim使用复数的绝对值和使用各种窗口函数,但它仍然不像我所瞄准的(Web Audio API演示):
import ddf.minim.analysis.*;
import ddf.minim.*;
Minim minim;
AudioInput in;
FFT fft;
float smoothing = 0;
float[] fftReal;
float[] fftImag;
float[] fftSmooth;
int specSize;
WindowFunction[] window = {FFT.NONE,FFT.HAMMING,FFT.HANN,FFT.COSINE,FFT.TRIANGULAR,FFT.BARTLETT,FFT.BARTLETTHANN,FFT.LANCZOS,FFT.BLACKMAN,FFT.GAUSS};
String[] wlabel = {"NONE","HAMMING","HANN","COSINE","TRIANGULAR","BARTLETT","BARTLETTHANN","LANCZOS","BLACKMAN","GAUSS"};
int windex = 0;
void setup(){
size(640, 360, P3D);
minim = new Minim(this);
in = minim.getLineIn(Minim.STEREO, 512);
fft = new FFT(in.bufferSize(), in.sampleRate());
fft.window(window[windex]);
specSize = fft.specSize();
fftSmooth = new float[specSize];
fftReal = new float[specSize];
colorMode(HSB,specSize,100,100);
}
void draw(){
background(0);
stroke(255);
fft.forward( in.mix);
fftReal = fft.getSpectrumReal();
fftImag = fft.getSpectrumImaginary();
for(int i = 0; i < specSize; i++)
{
float band = fft.getBand(i);
//Sw = abs(Sw(1:(1+N/2))); %# abs is sqrt(real^2 + imag^2)
float abs = sqrt(fftReal[i]*fftReal[i] + fftImag[i]*fftImag[i]);
fftSmooth[i] *= smoothing;
if(fftSmooth[i] < abs) fftSmooth[i] = abs;
stroke(i,100,50);
line( i, height, i, height - fftSmooth[i]*8 );
stroke(i,100,100);
line( i, height, i, height - band*8 );
}
text("smoothing: " + (int)(smoothing*100)+"\nwindow:"+wlabel[windex],10,10);
}
void keyPressed(){
float inc = 0.01;
if(keyCode == UP && smoothing < 1-inc) smoothing += inc;
if(keyCode == DOWN && smoothing > inc) smoothing -= inc;
if(key == 'W' && windex < window.length-1) windex++;
if(key == 'w' && windex > 0) windex--;
if(key == 'w' || key == 'W') fft.window(window[windex]);
}
我不确定我是否正确使用窗口函数,因为我没有注意到它们之间有很大的区别。复数的绝对值是正确的吗?如何获得更接近我的目标的可视化效果?
更新3:
我尝试应用@wakjah的有用提示,如下:
import ddf.minim.analysis.*;
import ddf.minim.*;
Minim minim;
AudioInput in;
FFT fft;
float smoothing = 0;
float[] fftReal;
float[] fftImag;
float[] fftSmooth;
float[] fftPrev;
float[] fftCurr;
int specSize;
WindowFunction[] window = {FFT.NONE,FFT.HAMMING,FFT.HANN,FFT.COSINE,FFT.TRIANGULAR,FFT.BARTLETT,FFT.BARTLETTHANN,FFT.LANCZOS,FFT.BLACKMAN,FFT.GAUSS};
String[] wlabel = {"NONE","HAMMING","HANN","COSINE","TRIANGULAR","BARTLETT","BARTLETTHANN","LANCZOS","BLACKMAN","GAUSS"};
int windex = 0;
int scale = 10;
void setup(){
minim = new Minim(this);
in = minim.getLineIn(Minim.STEREO, 512);
fft = new FFT(in.bufferSize(), in.sampleRate());
fft.window(window[windex]);
specSize = fft.specSize();
fftSmooth = new float[specSize];
fftPrev = new float[specSize];
fftCurr = new float[specSize];
size(specSize, specSize/2);
colorMode(HSB,specSize,100,100);
}
void draw(){
background(0);
stroke(255);
fft.forward( in.mix);
fftReal = fft.getSpectrumReal();
fftImag = fft.getSpectrumImaginary();
for(int i = 0; i < specSize; i++)
{
//float band = fft.getBand(i);
//Sw = abs(Sw(1:(1+N/2))); %# abs is sqrt(real^2 + imag^2)
//float abs = sqrt(fftReal[i]*fftReal[i] + fftImag[i]*fftImag[i]);
//fftSmooth[i] *= smoothing;
//if(fftSmooth[i] < abs) fftSmooth[i] = abs;
//x_dB = 10 * log10(real(x) ^ 2 + imag(x) ^ 2);
fftCurr[i] = scale * (float)Math.log10(fftReal[i]*fftReal[i] + fftImag[i]*fftImag[i]);
//Y[k] = alpha * Y_(t-1)[k] + (1 - alpha) * X[k]
fftSmooth[i] = smoothing * fftPrev[i] + ((1 - smoothing) * fftCurr[i]);
fftPrev[i] = fftCurr[i];//
stroke(i,100,100);
line( i, height, i, height - fftSmooth[i]);
}
text("smoothing: " + (int)(smoothing*100)+"\nwindow:"+wlabel[windex]+"\nscale:"+scale,10,10);
}
void keyPressed(){
float inc = 0.01;
if(keyCode == UP && smoothing < 1-inc) smoothing += inc;
if(keyCode == DOWN && smoothing > inc) smoothing -= inc;
if(key == 'W' && windex < window.length-1) windex++;
if(key == 'w' && windex > 0) windex--;
if(key == 'w' || key == 'W') fft.window(window[windex]);
if(keyCode == LEFT && scale > 1) scale--;
if(keyCode == RIGHT) scale++;
}
我不确定我是否按照意图应用了提示。以下是我的输出方式:
Windows Media Player 中的频谱。
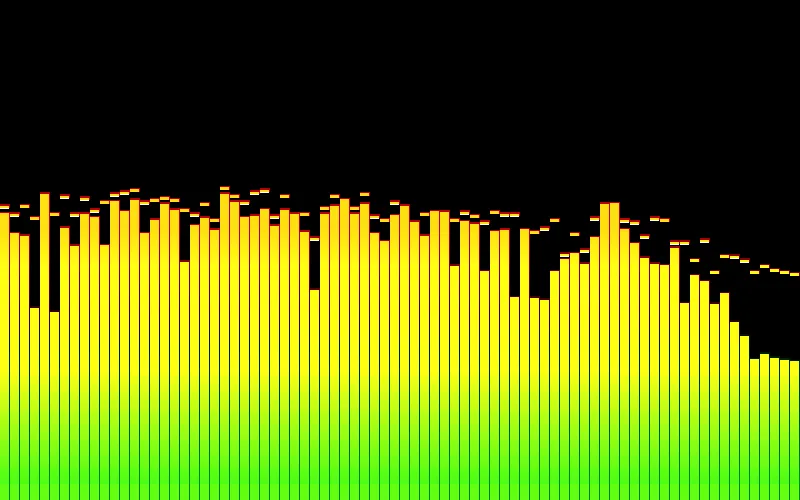
我不确定我是否正确应用了对数刻度。我的假设是,使用log10后(暂时忽略平滑),我会得到类似于我想要的绘图。
更新4:
import ddf.minim.analysis.*;
import ddf.minim.*;
Minim minim;
AudioInput in;
FFT fft;
float smoothing = 0;
float[] fftReal;
float[] fftImag;
float[] fftSmooth;
float[] fftPrev;
float[] fftCurr;
int specSize;
WindowFunction[] window = {FFT.NONE,FFT.HAMMING,FFT.HANN,FFT.COSINE,FFT.TRIANGULAR,FFT.BARTLETT,FFT.BARTLETTHANN,FFT.LANCZOS,FFT.BLACKMAN,FFT.GAUSS};
String[] wlabel = {"NONE","HAMMING","HANN","COSINE","TRIANGULAR","BARTLETT","BARTLETTHANN","LANCZOS","BLACKMAN","GAUSS"};
int windex = 0;
int scale = 10;
void setup(){
minim = new Minim(this);
in = minim.getLineIn(Minim.STEREO, 512);
fft = new FFT(in.bufferSize(), in.sampleRate());
fft.window(window[windex]);
specSize = fft.specSize();
fftSmooth = new float[specSize];
fftPrev = new float[specSize];
fftCurr = new float[specSize];
size(specSize, specSize/2);
colorMode(HSB,specSize,100,100);
}
void draw(){
background(0);
stroke(255);
fft.forward( in.mix);
fftReal = fft.getSpectrumReal();
fftImag = fft.getSpectrumImaginary();
for(int i = 0; i < specSize; i++)
{
float maxVal = Math.max(Math.abs(fftReal[i]), Math.abs(fftImag[i]));
if (maxVal != 0.0f) { // prevent divide-by-zero
// Normalize
fftReal[i] = fftReal[i] / maxVal;
fftImag[i] = fftImag[i] / maxVal;
}
fftCurr[i] = -scale * (float)Math.log10(fftReal[i]*fftReal[i] + fftImag[i]*fftImag[i]);
fftSmooth[i] = smoothing * fftSmooth[i] + ((1 - smoothing) * fftCurr[i]);
stroke(i,100,100);
line( i, height/2, i, height/2 - (mousePressed ? fftSmooth[i] : fftCurr[i]));
}
text("smoothing: " + (int)(smoothing*100)+"\nwindow:"+wlabel[windex]+"\nscale:"+scale,10,10);
}
void keyPressed(){
float inc = 0.01;
if(keyCode == UP && smoothing < 1-inc) smoothing += inc;
if(keyCode == DOWN && smoothing > inc) smoothing -= inc;
if(key == 'W' && windex < window.length-1) windex++;
if(key == 'w' && windex > 0) windex--;
if(key == 'w' || key == 'W') fft.window(window[windex]);
if(keyCode == LEFT && scale > 1) scale--;
if(keyCode == RIGHT) scale++;
}
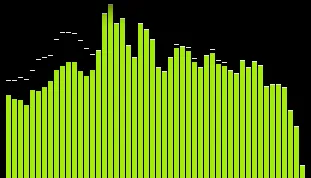
产生这个:
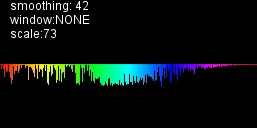
更新6
import ddf.minim.analysis.*;
import ddf.minim.*;
Minim minim;
AudioInput in;
FFT fft;
float smoothing = 0;
float[] fftReal;
float[] fftImag;
float[] fftSmooth;
float[] fftPrev;
float[] fftCurr;
int specSize;
WindowFunction[] window = {FFT.NONE,FFT.HAMMING,FFT.HANN,FFT.COSINE,FFT.TRIANGULAR,FFT.BARTLETT,FFT.BARTLETTHANN,FFT.LANCZOS,FFT.BLACKMAN,FFT.GAUSS};
String[] wlabel = {"NONE","HAMMING","HANN","COSINE","TRIANGULAR","BARTLETT","BARTLETTHANN","LANCZOS","BLACKMAN","GAUSS"};
int windex = 0;
int scale = 10;
void setup(){
minim = new Minim(this);
in = minim.getLineIn(Minim.STEREO, 512);
fft = new FFT(in.bufferSize(), in.sampleRate());
fft.window(window[windex]);
specSize = fft.specSize();
fftSmooth = new float[specSize];
fftPrev = new float[specSize];
fftCurr = new float[specSize];
size(specSize, specSize/2);
colorMode(HSB,specSize,100,100);
}
void draw(){
background(0);
stroke(255);
fft.forward( in.mix);
fftReal = fft.getSpectrumReal();
fftImag = fft.getSpectrumImaginary();
for(int i = 0; i < specSize; i++)
{
fftCurr[i] = scale * (float)Math.log10(fftReal[i]*fftReal[i] + fftImag[i]*fftImag[i]);
fftSmooth[i] = smoothing * fftSmooth[i] + ((1 - smoothing) * fftCurr[i]);
stroke(i,100,100);
line( i, height/2, i, height/2 - (mousePressed ? fftSmooth[i] : fftCurr[i]));
}
text("smoothing: " + (int)(smoothing*100)+"\nwindow:"+wlabel[windex]+"\nscale:"+scale,10,10);
}
void keyPressed(){
float inc = 0.01;
if(keyCode == UP && smoothing < 1-inc) smoothing += inc;
if(keyCode == DOWN && smoothing > inc) smoothing -= inc;
if(key == 'W' && windex < window.length-1) windex++;
if(key == 'w' && windex > 0) windex--;
if(key == 'w' || key == 'W') fft.window(window[windex]);
if(keyCode == LEFT && scale > 1) scale--;
if(keyCode == RIGHT) scale++;
if(key == 's') saveFrame("fftmod.png");
}
这感觉如此接近:
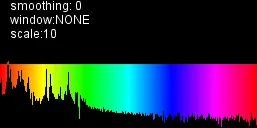
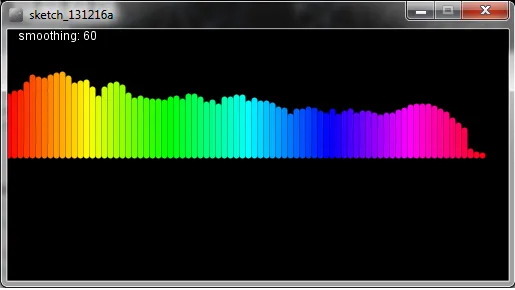 增强功能:现在带有A加权
增强功能:现在带有A加权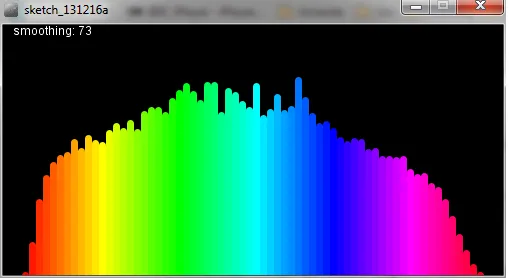
-是不必要的... 进行归一化和dB转换两者都做可能也是不必要的。如果删除-不起作用,请尝试只进行归一化而不进行dB转换(从您提供的样本来看,这似乎是您正在尝试复制的样本所采用的方法)。 - wakjah