我在使用Pandas将DataFrame写入SQL数据库时遇到了性能问题。为了尽可能地提高速度,我使用memSQL(它类似于MySQL的代码,因此我不需要做任何事情)。我刚刚对我的实例进行了基准测试:
那并不光彩,只是我的本地笔记本电脑。我知道...我也在使用root用户,但这是一个临时的Docker容器。
以下是将我的DataFrame写入数据库的代码:
以下是该函数的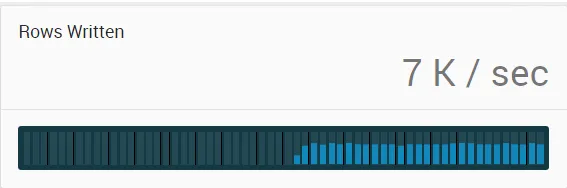 我还增加了
我还增加了
以下是DataFrame的形状:
有人知道我如何让它更快吗?
docker run --rm -it --link=memsql:memsql memsql/quickstart simple-benchmark
Creating database simple_benchmark
Warming up workload
Launching 10 workers
Workload will take approximately 30 seconds.
Stopping workload
42985000 rows inserted using 10 threads
1432833.3 rows per second
那并不光彩,只是我的本地笔记本电脑。我知道...我也在使用root用户,但这是一个临时的Docker容器。
以下是将我的DataFrame写入数据库的代码:
import MySQLdb
import mysql.connector
from sqlalchemy import create_engine
from pandas.util.testing import test_parallel
engine = create_engine('mysql+mysqlconnector://root@localhost:3306/netflow_test', echo=False)
# max_allowed_packet = 1000M in mysql.conf
# no effect
# @test_parallel(num_threads=8)
def commit_flows(netflow_df2):
% time netflow_df2.to_sql(name='netflow_ids', con=engine, if_exists = 'append', index=False, chunksize=500)
commit_flows(netflow_df2)
以下是该函数的
%time测量结果。
多线程不能使其更快,它仍保持在7000-8000行/秒。
屏幕截图:CPU时间:用户2分6秒,系统1.69秒,总计2分8秒。墙上时间:2分18秒。
我还增加了max_allowed_packet大小以批量提交,并使用更大的块大小,但仍然没有更快。以下是DataFrame的形状:
netflow_df2.shape
(1015391, 20)
有人知道我如何让它更快吗?