我正在尝试解决一个Rosalind基础问题,即计算给定序列中核苷酸的数量,并将结果返回到列表中。对于那些不熟悉生物信息学的人来说,它只是在字符串内计算4个不同字符('A','C','G','T')出现的次数。
我期望使用collections.Counter是最快的方法(首先因为他们声称具有高性能,其次是因为我看到很多人在使用此特定问题),但令我惊讶的是,这种方法是最慢的!
我比较了三种不同的方法,使用timeit并运行两种类型的实验:
- 运行几次长序列 - 运行很多次短序列
以下是我的代码:
我期望使用collections.Counter是最快的方法(首先因为他们声称具有高性能,其次是因为我看到很多人在使用此特定问题),但令我惊讶的是,这种方法是最慢的!
我比较了三种不同的方法,使用timeit并运行两种类型的实验:
- 运行几次长序列 - 运行很多次短序列
以下是我的代码:
import timeit
from collections import Counter
# Method1: using count
def method1(seq):
return [seq.count('A'), seq.count('C'), seq.count('G'), seq.count('T')]
# method 2: using a loop
def method2(seq):
r = [0, 0, 0, 0]
for i in seq:
if i == 'A':
r[0] += 1
elif i == 'C':
r[1] += 1
elif i == 'G':
r[2] += 1
else:
r[3] += 1
return r
# method 3: using Collections.counter
def method3(seq):
counter = Counter(seq)
return [counter['A'], counter['C'], counter['G'], counter['T']]
if __name__ == '__main__':
# Long dummy sequence
long_seq = 'ACAGCATGCA' * 10000000
# Short dummy sequence
short_seq = 'ACAGCATGCA' * 1000
# Test 1: Running a long sequence once
print timeit.timeit("method1(long_seq)", setup='from __main__ import method1, long_seq', number=1)
print timeit.timeit("method2(long_seq)", setup='from __main__ import method2, long_seq', number=1)
print timeit.timeit("method3(long_seq)", setup='from __main__ import method3, long_seq', number=1)
# Test2: Running a short sequence lots of times
print timeit.timeit("method1(short_seq)", setup='from __main__ import method1, short_seq', number=10000)
print timeit.timeit("method2(short_seq)", setup='from __main__ import method2, short_seq', number=10000)
print timeit.timeit("method3(short_seq)", setup='from __main__ import method3, short_seq', number=10000)
结果:
Test1:
Method1: 0.224009990692
Method2: 13.7929501534
Method3: 18.9483819008
Test2:
Method1: 0.224207878113
Method2: 13.8520510197
Method3: 18.9861831665
对于两个实验,方法1比方法2和3都快得多,这是我的问题:
我是否做错了什么或者确实比其他两种方法慢?有人能运行相同的代码并分享结果吗?
如果我的结果是正确的,(也许这应该是另一个问题),是否有比使用方法1更快的方法来解决这个问题?
如果
count更快,则collections.Counter有什么问题?
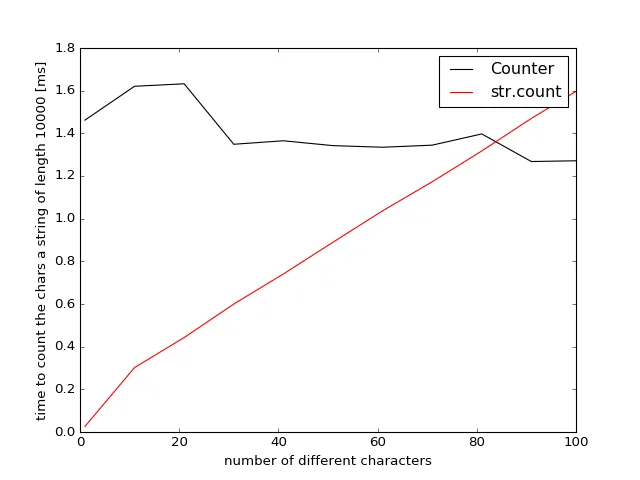
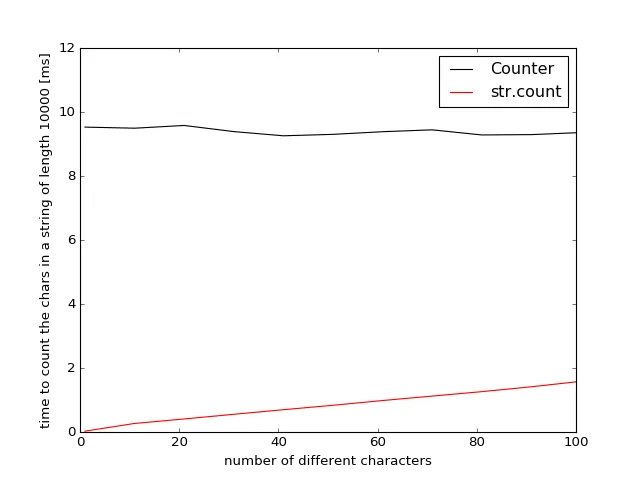
counter比方法2更快,而方法2是,无意冒犯,糟糕的代码。 - Ma0