你给了我解决一直以来困扰我的问题的方法。很好的方法,一个小技巧让我的程序也能工作了!
我相信一定有很多Deep用户试图使用超过两个权重,比如weights=(-1.0, -1.0, 1.0)。
我将发布一个简单的例子,其中有3个参数(2个参数最小化,1个参数最大化)。
from numpy import array
import numpy
import random
from deap import base, creator, tools, algorithms
IND_INIT_SIZE = 5
MAX_WEIGHT = 2000
MAX_SIZE = 1500
r = array([[213, 508, 22],
[594, 354, 50],
[275, 787, 43],
[652, 218, 46],
[728, 183, 43],
[856, 308, 33],
[727, 482, 45],
[762, 683, 26],
[707, 450, 19],
[909, 309, 45],
[979, 247, 42],
[259, 705, 42],
[260, 543, 14],
[899, 825, 17],
[446, 360, 35],
[491, 818, 47],
[647, 404, 17],
[604, 623, 32],
[900, 840, 45],
[374, 127, 33]] )
NBR_ITEMS = r.shape[0]
items = {}
for i in range(NBR_ITEMS):
items[i] = ( r[i][0] , r[i][1] , r[i][2] )
creator.create("Fitness", base.Fitness, weights=(-1.0, 1.0 ))
creator.create("Individual", set, fitness=creator.Fitness)
toolbox = base.Toolbox()
toolbox.register("attr_item", random.randrange, NBR_ITEMS)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_item, n=IND_INIT_SIZE)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
def evaluation(individual):
weight = 0.0
size =0.0
value = 0.0
for item in individual:
weight += items[item][0]
size += items[item][1]
value += items[item][2]
if weight > MAX_WEIGHT or size > MAX_SIZE:
return 10000, 0
if value == 0:
value = 0.0000001
MinFitess_score = weight + size
MaxFitenss_score = value
return MinFitess_score , MaxFitenss_score,
def cxSet(ind1, ind2):
"""Apply a crossover operation on input sets. The first child is the
intersection of the two sets, the second child is the difference of the
two sets.
"""
temp = set(ind1)
ind1 &= ind2
ind2 ^= temp
return ind1, ind2
def mutSet(individual):
"""Mutation that pops or add an element."""
if random.random() < 0.5:
if len(individual) > 0:
individual.remove(random.choice(sorted(tuple(individual))))
else:
individual.add(random.randrange(NBR_ITEMS))
return individual,
toolbox.register("mate", cxSet)
toolbox.register("mutate", mutSet)
toolbox.register("select", tools.selNSGA2)
toolbox.register("evaluate", evaluation)
def main():
ngen = 300
pop = toolbox.population(n= 300)
hof = tools.ParetoFront()
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean, axis=0)
stats.register("std", numpy.std, axis=0)
stats.register("min", numpy.min, axis=0)
stats.register("max", numpy.max, axis=0)
algorithms.eaSimple(pop, toolbox, 0.7, 0.2, ngen=ngen, stats=stats, halloffame=hof, verbose=True)
return hof, pop
if __name__ == "__main__":
hof, pop = main()
print(hof)
理想结果:
- 个体({1, 2, 19, 4}) 或
- 个体({1, 2, 19, 3})
因为它们的总分非常相似,所以您将获得其中一个结果。
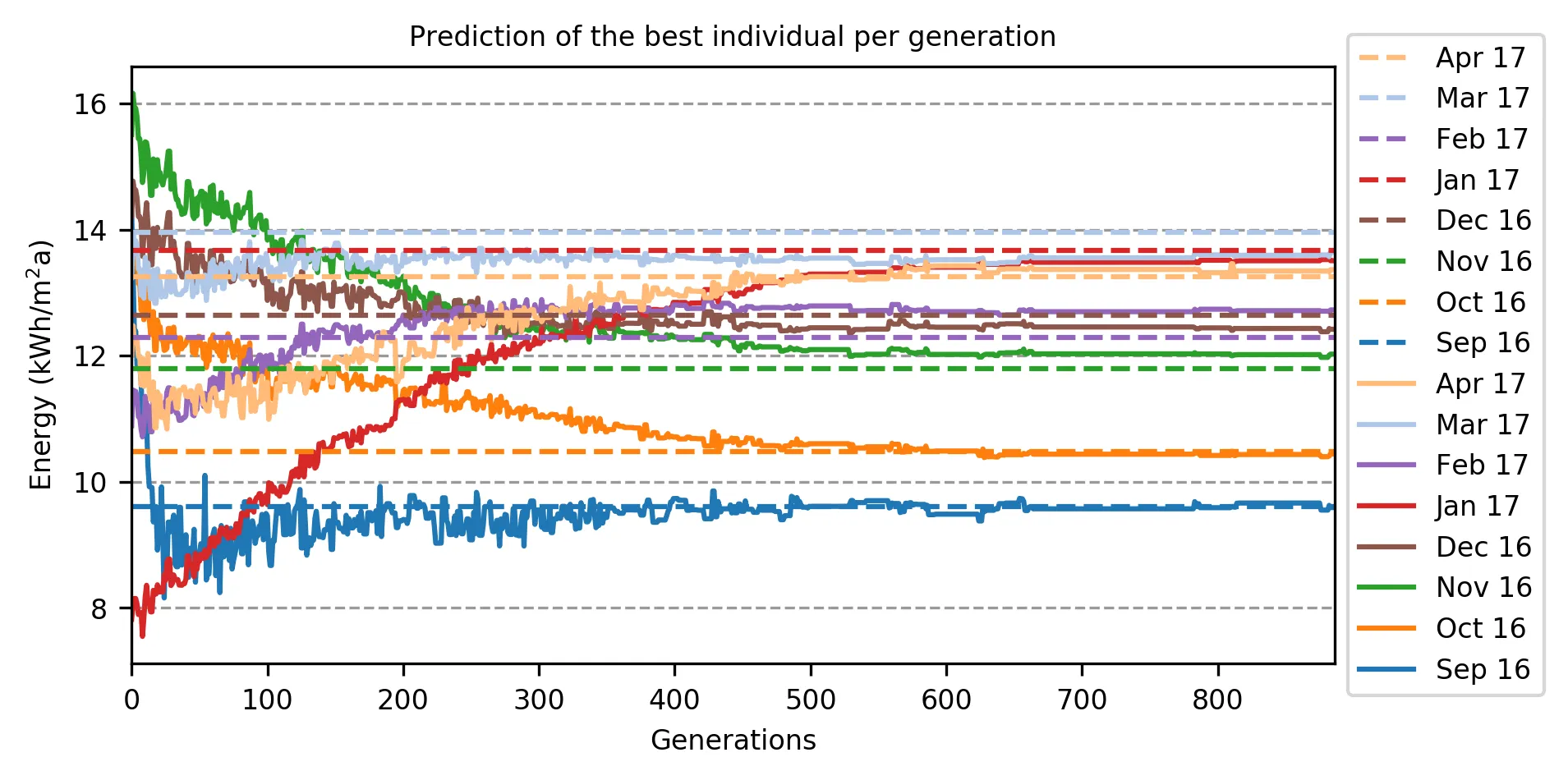
 月度目标结果:
月度目标结果: