我想将这个csv文件格式转换为:

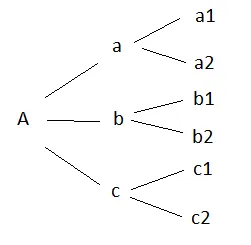
我想将这个csv文件格式转换为:
collections.defaultdict 来使用嵌套字典:from collections import defaultdict
import pandas as pd
# read csv file
# df = pd.read_csv('input.csv', header=None)
df = pd.DataFrame([['A', 'a', 'a1'],
['A', 'a', 'a2'],
['A', 'b', 'b1'],
['A', 'b', 'b2'],
['A', 'c', 'c1'],
['A', 'c', 'c2']],
columns=['col1', 'col2', 'col3'])
d = defaultdict(lambda: defaultdict(list))
for row in df.itertuples():
d[row[1]][row[2]].append(row[3])
结果
defaultdict(<function __main__.<lambda>>,
{'A': defaultdict(list,
{'a': ['a1', 'a2'],
'b': ['b1', 'b2'],
'c': ['c1', 'c2']})})
谢谢,我会看一下 defaultdict。我的解决方案可能更加hacky,但如果有人需要可定制的东西:
import pandas as pd
df = pd.DataFrame([['A', 'a', 'a1'],
['A', 'a', 'a2'],
['A', 'b', 'b1'],
['A', 'b', 'b2'],
['A', 'c', 'c1'],
['A', 'c', 'c2']],
columns=['col1', 'col2', 'col3'])
cols = ['col1', 'col2', 'col3']
children = {p : {} for p in cols}
parent = {p : {} for p in cols}
for x in df.iterrows():
for i in range(len(cols)-1):
_parent = x[1][cols[i]]
_child = x[1][cols[i+1]]
parent[cols[i+1]].update({_child : _parent})
if _parent in children[cols[i]]:
children_list = children[cols[i]][_parent]
children_list.add(_child)
children[cols[i]].update({_parent : children_list})
else:
children[cols[i]].update({_parent : set([_child])})
结果:
parent =
{'col1': {},
'col2': {'a': 'A', 'b': 'A', 'c': 'A'},
'col3': {'a1': 'a', 'a2': 'a', 'b1': 'b', 'b2': 'b', 'c1': 'c', 'c2': 'c'}}
然后您可以在层级结构中上下移动。
pandas、numpy等在内存中执行。我不知道你的数据有多大,所以无法确定哪种方法适合你。 - jpp