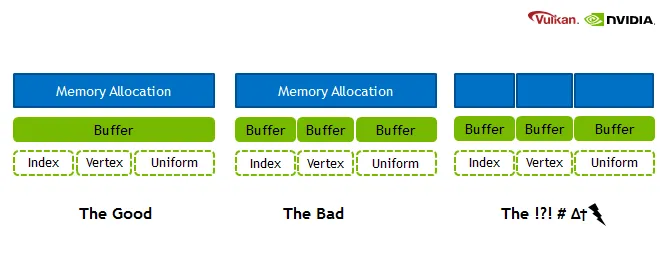
在Vulkan中,内存管理的推荐方法是对缓冲区进行子分配,例如下面的图片所示。
我正在尝试实现“好”的方法。我已经有了一个系统,可以告诉我在内存分配中哪里可用,因此我可以绑定单个大缓冲区的子区域。 然而,我找不到执行此操作的机制,或者只是误解了发生的情况,因为绑定函数以缓冲区和偏移量作为输入。我无法看到如何指定绑定的大小,除非通过现有缓冲区。
所以我有几个问题:
任何指针都非常感激!
我正在尝试实现“好”的方法。我已经有了一个系统,可以告诉我在内存分配中哪里可用,因此我可以绑定单个大缓冲区的子区域。 然而,我找不到执行此操作的机制,或者只是误解了发生的情况,因为绑定函数以缓冲区和偏移量作为输入。我无法看到如何指定绑定的大小,除非通过现有缓冲区。
所以我有几个问题:
- 下面图像中的点状矩形只是绑定,还是额外的缓冲区?
- 如果它们是绑定,如何告诉Vulkan(最好使用VMA)使用缓冲区的该子段?
- 如果它们是额外的缓冲区,如何创建它们?
- 如果两者都不是,那它们是什么?
任何指针都非常感激!