考虑一组数字:
现在,我可以使用简单的Python循环来完成这个任务:
In [8]: import numpy as np
In [9]: x = np.array([np.random.random() for i in range(10)])
In [10]: x
Out[10]:
array([ 0.62594394, 0.03255799, 0.7768568 , 0.03050498, 0.01951657,
0.04767246, 0.68038553, 0.60036203, 0.3617409 , 0.80294355])
现在我想按照以下方式将这个集合转换为另一个集合y:对于x中的每个元素i,y中相应的元素j将是i之前比i小的元素的数量。例如,上述给定的x会变成:
In [25]: y
Out[25]: array([ 6., 2., 8., 1., 0., 3., 7., 5., 4., 9.])
现在,我可以使用简单的Python循环来完成这个任务:
In [16]: for i in range(len(x)):
...: tot = 0
...: for j in range(len(x)):
...: if x[i] > x[j]: tot += 1
...: y[i] = int(tot)
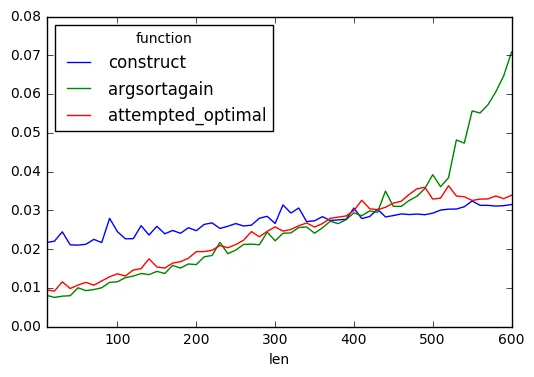
然而,当x的长度非常大时,代码会变得极其缓慢。我想知道是否有任何numpy魔法可以营救。例如,如果我必须过滤所有小于0.5的元素,我只需使用布尔掩码:
In [19]: z = x[x < 0.5]
In [20]: z
Out[20]: array([ 0.03255799, 0.03050498, 0.01951657, 0.04767246, 0.3617409 ])
可以使用类似的东西来实现更快速地达到相同的目的吗?
np.random.rand(10)。 - Andras Deak -- Слава Україніx = np.random.rand(10),你会发现在列表推导式中不必调用random():) - Andras Deak -- Слава Україні