我需要将一组数字分成两组,使得一组中的任何数字的因子都不是另一组中任何数字的因子。我认为我们只需要找到这样的组,使得每个组中数字的乘积的最大公约数为1。例如 - 如果我们有列表2,3,4,5,6,7,9,则可能的组合方式如下:(2,3,4,6,9)(5,7)、(2,3,4,5,6,9)(7)、(2,3,4,6,7,9)(5)。
我最初想做的是 -
我的问题是关于算法的,伪代码也可以,我不需要完整的代码。然而,我熟悉Python、Fortran、C、BASH和Octave,因此这些语言中的答案也会有所帮助,但是正如我所说,语言不是关键点。如果有必要,可以帮我修改措辞,让我的问题更好。
我最初想做的是 -
- 生成一个素数列表,其中包含列表中的最大数字。
- 逐一用每个素数除以列表中的所有元素,并为不能被该素数整除的数字赋值0,否则赋值1。
- 对所有素数重复此操作,得到一个由零和一组成的矩阵。
- 从第一个素数开始,将具有1的所有元素放入同一组。
- 如果两个组具有相同的元素,则将它们合并成一个单一的组。
- 计算这些组可以组合的可能方法总数,并完成。
- 素数列表 = [2,3,5,7]
- 除法后,矩阵如下所示-
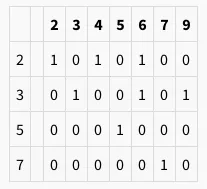
- 组=(2,4,6),(3,6,9),(5),(7)
- 合并后的组=(2,3,4,6,9),(5),(7)
- 最后,组合很容易,因为我只需要知道这些可以组合的方式总数。
我的问题是关于算法的,伪代码也可以,我不需要完整的代码。然而,我熟悉Python、Fortran、C、BASH和Octave,因此这些语言中的答案也会有所帮助,但是正如我所说,语言不是关键点。如果有必要,可以帮我修改措辞,让我的问题更好。