我正在使用Keras为情感分析创建一个LSTM,使用IMDB数据库的(子集)。如果我在最后一个密集层之前添加一个flatten层,我的训练、验证和测试准确性会显着提高:
def lstm_model_flatten():
embedding_dim = 128
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen))
model.add(layers.LSTM(128, return_sequences = True, dropout=0.2))
# Flatten layer
model.add(layers.Flatten())
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
return model
这会很快过拟合,但验证准确率可以达到约76%:
Model: "sequential_43"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_42 (Embedding) (None, 500, 128) 4768256
_________________________________________________________________
lstm_63 (LSTM) (None, 500, 128) 131584
_________________________________________________________________
flatten_10 (Flatten) (None, 64000) 0
_________________________________________________________________
dense_40 (Dense) (None, 1) 64001
=================================================================
Total params: 4,963,841
Trainable params: 4,963,841
Non-trainable params: 0
_________________________________________________________________
Epoch 1/7
14/14 [==============================] - 26s 2s/step - loss: 0.6911 - accuracy: 0.5290 - val_loss: 0.6802 - val_accuracy: 0.5650
Epoch 2/7
14/14 [==============================] - 23s 2s/step - loss: 0.6451 - accuracy: 0.6783 - val_loss: 0.6074 - val_accuracy: 0.6950
Epoch 3/7
14/14 [==============================] - 23s 2s/step - loss: 0.4594 - accuracy: 0.7910 - val_loss: 0.5237 - val_accuracy: 0.7300
Epoch 4/7
14/14 [==============================] - 23s 2s/step - loss: 0.2566 - accuracy: 0.9149 - val_loss: 0.4753 - val_accuracy: 0.7650
Epoch 5/7
14/14 [==============================] - 23s 2s/step - loss: 0.1397 - accuracy: 0.9566 - val_loss: 0.6011 - val_accuracy: 0.8050
Epoch 6/7
14/14 [==============================] - 23s 2s/step - loss: 0.0348 - accuracy: 0.9898 - val_loss: 0.7648 - val_accuracy: 0.8100
Epoch 7/7
14/14 [==============================] - 23s 2s/step - loss: 0.0136 - accuracy: 0.9955 - val_loss: 0.8829 - val_accuracy: 0.8150
如果在LSTM层上没有使用展开层(并且设置return_sequences = False),则仅能产生约50%的验证准确度。
在这篇文章的评论中建议在密集层之前使用return_sequences = False,而不是使用展开层。
但是为什么要这样做呢?如果使用展开层可以提高模型性能,是否可以使用它?展开层在这里到底起到了什么作用,并为什么会提高准确度?
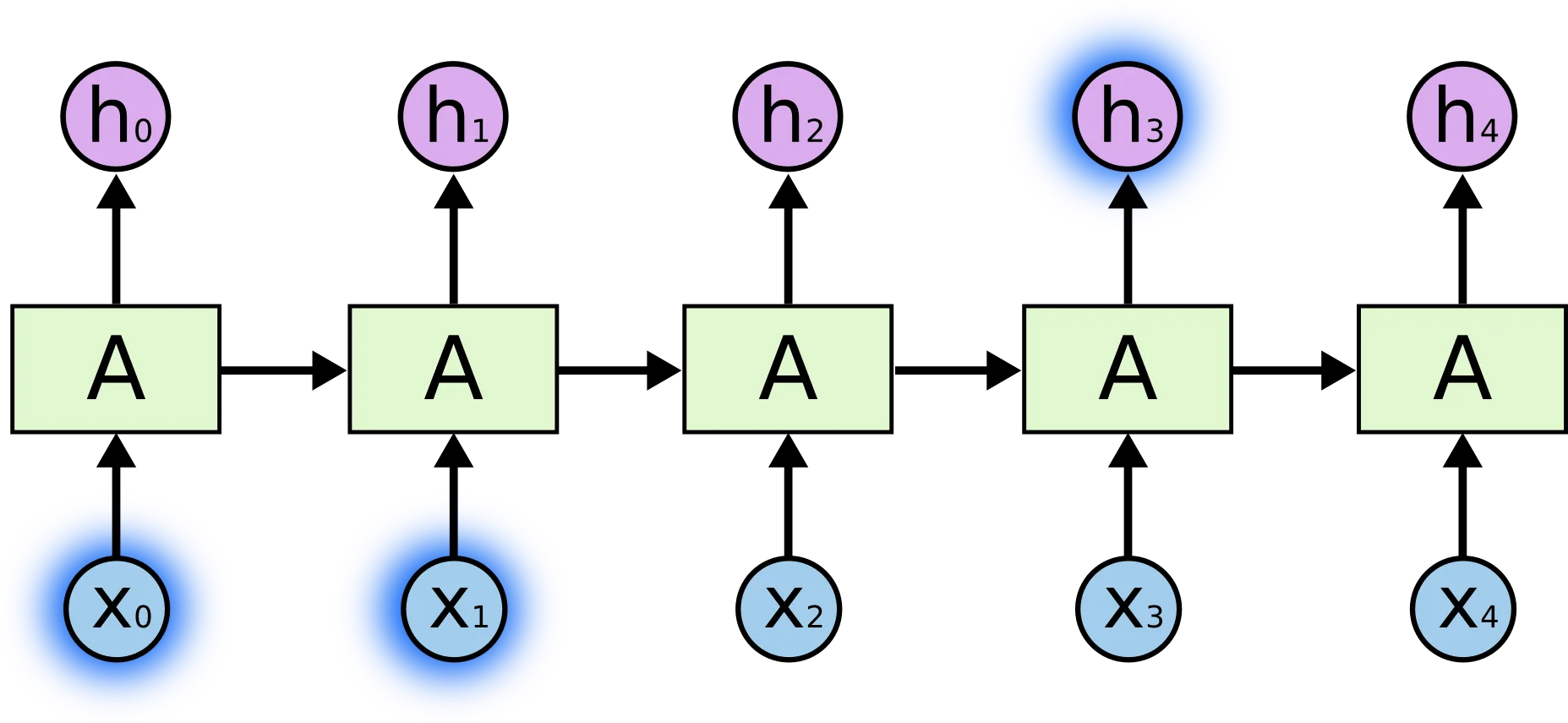
machine-learning标签信息中的介绍和注意事项。 - desertnautreturn_sequences = True而不是使用Flatten。return_sequences = True会使 LSTM 的每一步输出一个值而不仅仅是最后一步。这意味着网络的最后部分有更多的输出值可供使用。Flatten层只是改变了输出的维度形状。 - golmschenk