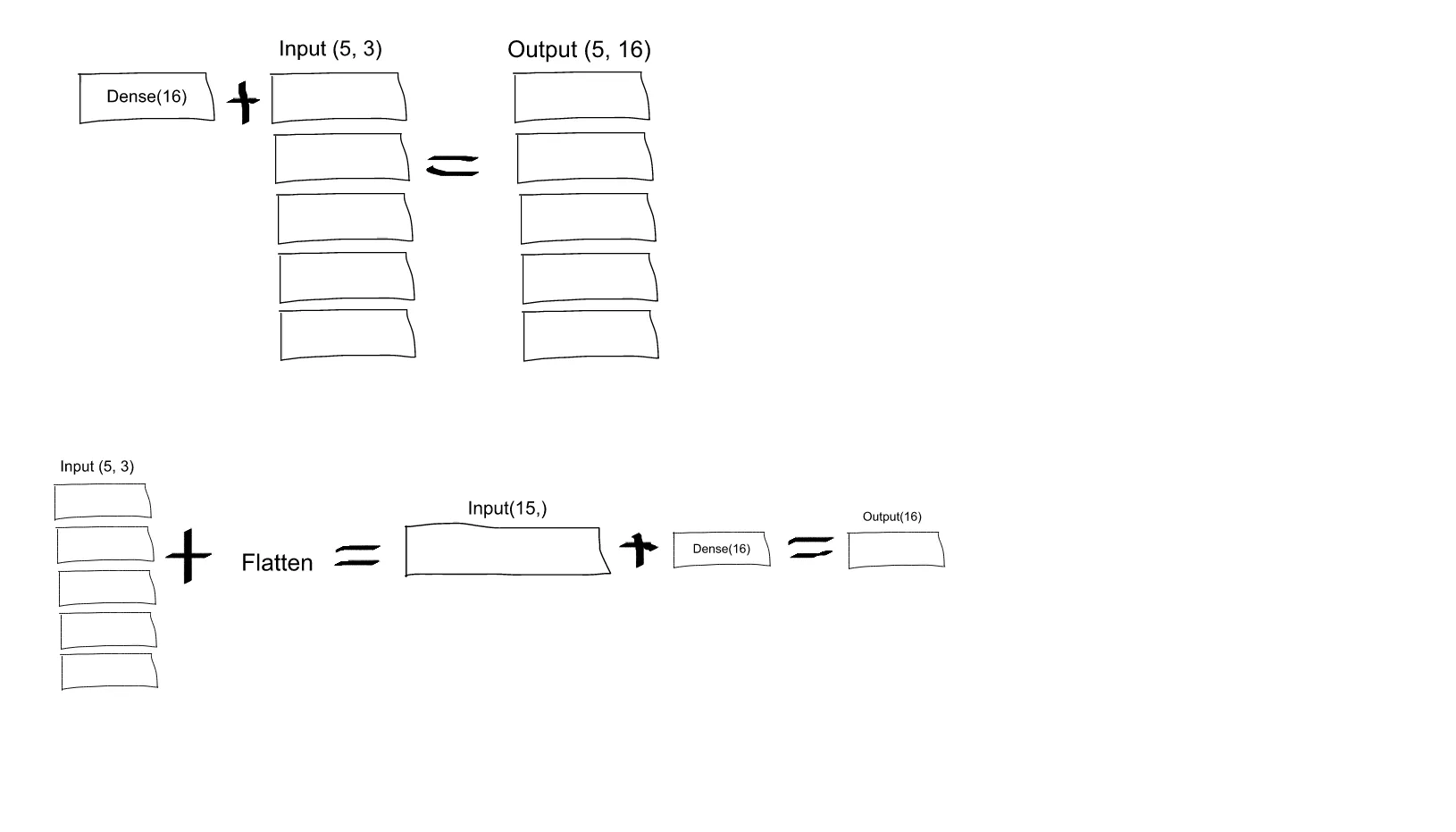
我正在尝试理解Keras中Flatten函数的作用。以下是我的代码,这是一个简单的两层神经网络。它接收形状为(3,2)的二维数据,并输出形状为(1,4)的一维数据:
model = Sequential()
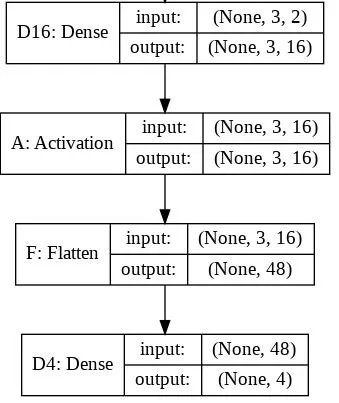
model.add(Dense(16, input_shape=(3, 2)))
model.add(Activation('relu'))
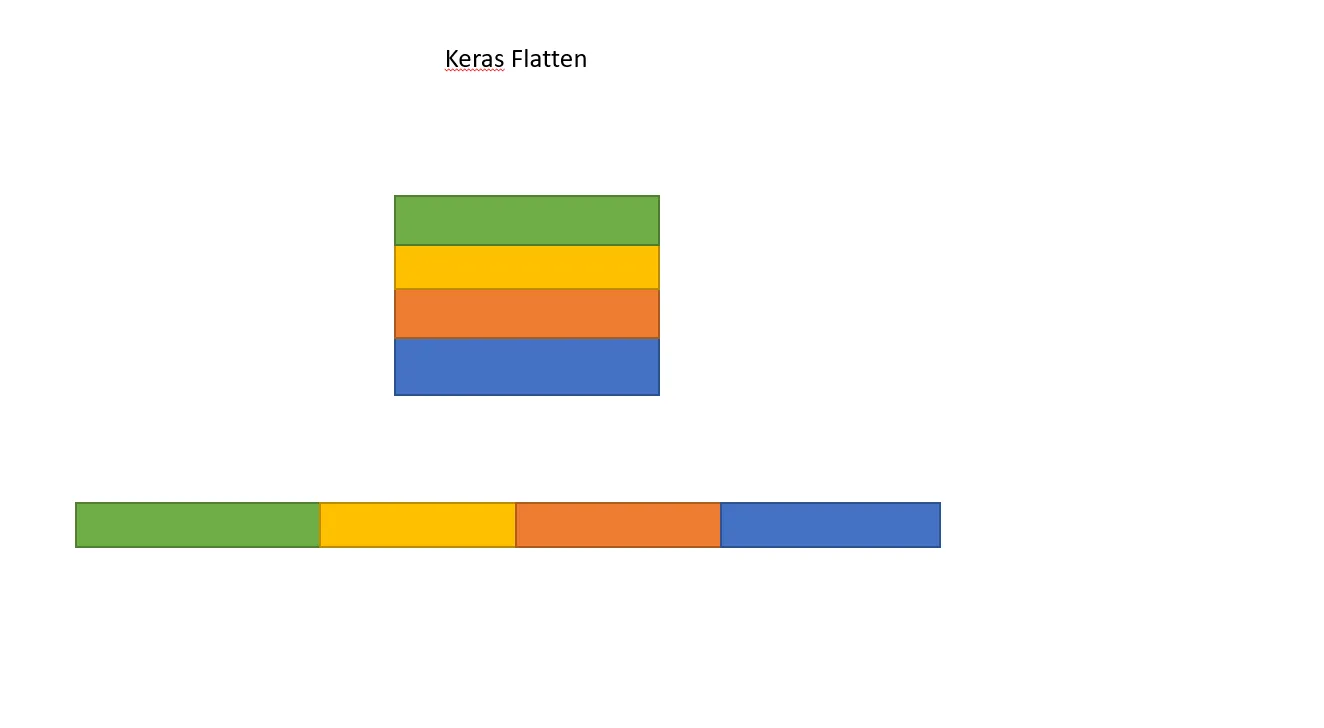
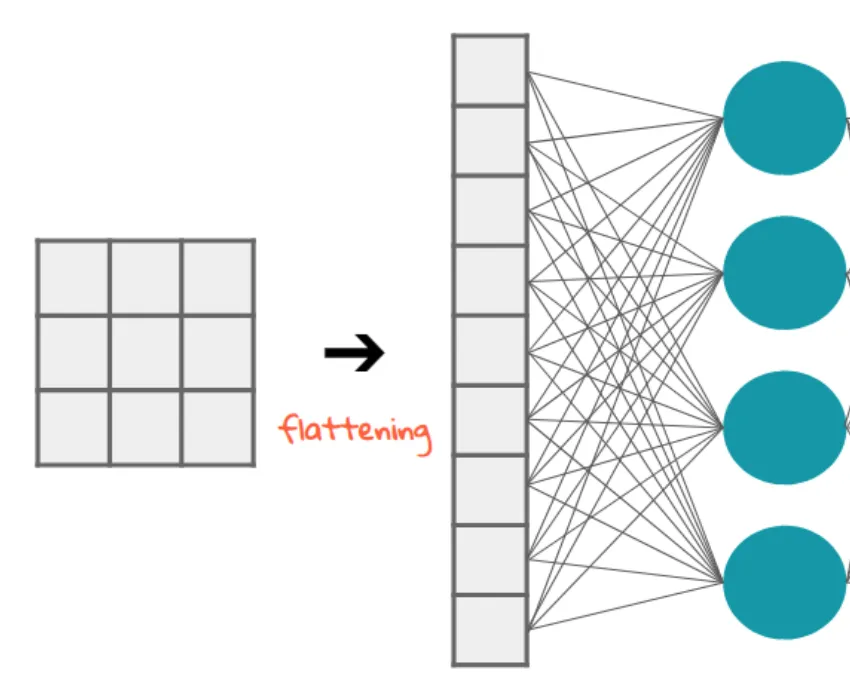
model.add(Flatten())
model.add(Dense(4))
model.compile(loss='mean_squared_error', optimizer='SGD')
x = np.array([[[1, 2], [3, 4], [5, 6]]])
y = model.predict(x)
print y.shape
这将打印出 y 的形状为 (1, 4)。然而,如果我移除 Flatten 行,那么它会打印出 y 的形状为 (1, 3, 4)。
我不理解这个问题。根据我对神经网络的理解,model.add(Dense(16, input_shape=(3, 2))) 函数创建了一个具有 16 个节点的隐藏全连接层。每个节点都与 3x2 个输入元素中的每个元素相连。因此,第一层的这 16 个节点已经是“扁平”的了。所以,第一层的输出形状应该是 (1, 16)。然后,第二层以此作为输入,输出形状为 (1, 4) 的数据。
因此,如果第一层的输出已经是“扁平”的且形状为 (1, 16),那么我为什么还需要进一步压缩它?
{kind=link}
{kind=link}