石灰解释器源代码: https://github.com/marcotcr/lime
树解释器源代码: tree interpreter
我正在尝试使用 Lime 和 treeinterpreter 来理解决策树是如何进行预测的。虽然两者都声称能够解释决策树,但似乎它们以不同的方式解释相同的决策树,即特征贡献的顺序。这怎么可能呢?如果两者都看着同一件事,并试图描述同一事件,为什么会按不同的顺序分配重要性。
我们应该信任谁?特别是在顶部功能确实对预测有影响的情况下。
树的代码
import sklearn
import sklearn.datasets
import sklearn.ensemble
import numpy as np
import lime
import lime.lime_tabular
from __future__ import print_function
np.random.seed(1)
from treeinterpreter import treeinterpreter as ti
from sklearn.tree import DecisionTreeClassifier
iris = sklearn.datasets.load_iris()
dt = DecisionTreeClassifier(random_state=42)
dt.fit(iris.data, iris.target)
n = 100
instances =iris.data[n].reshape(1,-1)
prediction, biases, contributions = ti.predict(dt, instances)
for i in range(len(instances)):
print ("prediction:",prediction)
print ("-"*20)
print ("Feature contributions:")
print ("-"*20)
for c, feature in sorted(zip(contributions[i],
iris.feature_names),
key=lambda x: ~abs(x[0].any())):
print (feature, c)
import sklearn
import sklearn.datasets
import sklearn.ensemble
import numpy as np
import lime
import lime.lime_tabular
from __future__ import print_function
np.random.seed(1)
from sklearn.tree import DecisionTreeClassifier
iris = sklearn.datasets.load_iris()
dt = DecisionTreeClassifier(random_state=42)
dt.fit(iris.data, iris.target)
explainer = lime.lime_tabular.LimeTabularExplainer(iris.data, feature_names=iris.feature_names,
class_names=iris.target_names,
discretize_continuous=False)
n = 100
exp = explainer.explain_instance(iris.data[n], dt.predict_proba, num_features=4, top_labels=2)
exp.show_in_notebook(show_table=True, predict_proba= True , show_predicted_value = True , show_all=False)
让我们首先看一下tree的输出结果。
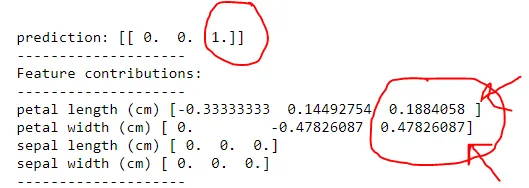
所以它确实正确地说是一个virginica。然而,通过在
1) 花瓣宽度(cm)然后花瓣长度(cm)中分配重要性
现在让我们看看lime的输出结果
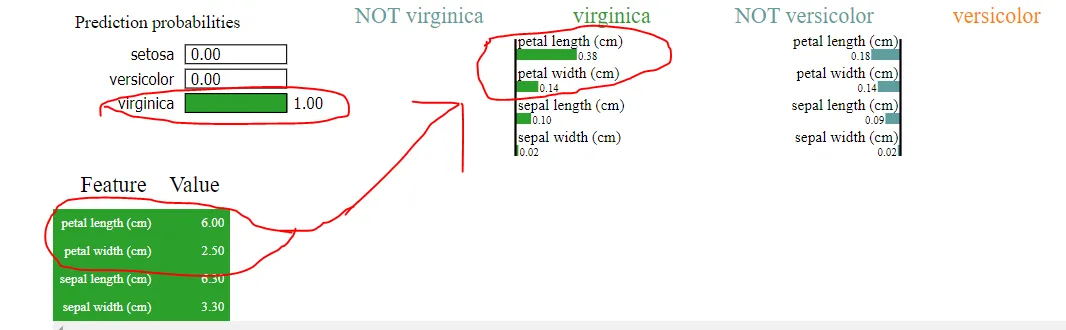
是的,它确实说算法预测了virginica,但是从它进行该分类的方式来看,我们清楚地看到以下内容
1) 在lime中,花瓣长度(cm)>花瓣宽度(cm),而不是在tree中显示的花瓣长度(cm)<花瓣宽度(cm)
2) 当萼片宽度和萼片长度被预测为零时,在lime中声称有确定的值,如上传的图像所示
这里发生了什么?
当特征是1000+时,问题变得更加复杂,每个数字都很重要。
random_state=50;你能确认在这个修改之后,你的图片中显示的确切数字仍然有效吗? - desertnaut