以下是决策树的一小段,因为它非常庞大。
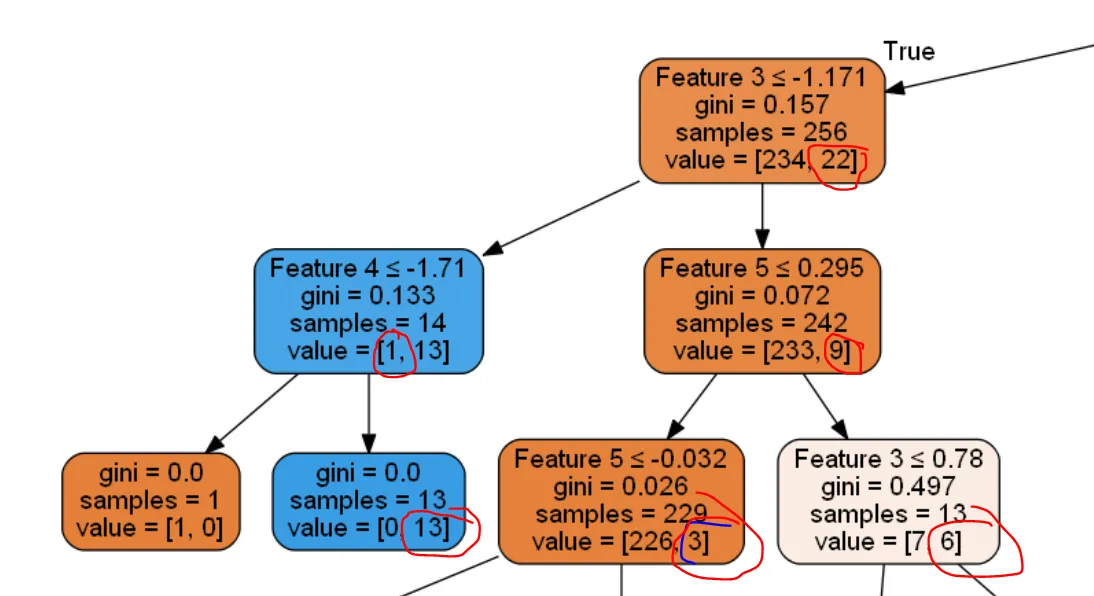
当节点中的最低值小于5时,如何停止树生长。这是生成决策树的代码。在SciKit - Decision Tree中,我们可以看到实现此操作的唯一方法是通过min_impurity_decrease,但我不确定它具体是如何工作的。
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_classification(n_samples=1000,
n_features=6,
n_informative=3,
n_classes=2,
random_state=0,
shuffle=False)
# Creating a dataFrame
df = pd.DataFrame({'Feature 1':X[:,0],
'Feature 2':X[:,1],
'Feature 3':X[:,2],
'Feature 4':X[:,3],
'Feature 5':X[:,4],
'Feature 6':X[:,5],
'Class':y})
y_train = df['Class']
X_train = df.drop('Class',axis = 1)
dt = DecisionTreeClassifier( random_state=42)
dt.fit(X_train, y_train)
from IPython.display import display, Image
import pydotplus
from sklearn import tree
from sklearn.tree import _tree
from sklearn import tree
import collections
import drawtree
import os
os.environ["PATH"] += os.pathsep + 'C:\\Anaconda3\\Library\\bin\\graphviz'
dot_data = tree.export_graphviz(dt, out_file = 'thisIsTheImagetree.dot',
feature_names=X_train.columns, filled = True
, rounded = True
, special_characters = True)
graph = pydotplus.graph_from_dot_file('thisIsTheImagetree.dot')
thisIsTheImage = Image(graph.create_png())
display(thisIsTheImage)
#print(dt.tree_.feature)
from subprocess import check_call
check_call(['dot','-Tpng','thisIsTheImagetree.dot','-o','thisIsTheImagetree.png'])
更新
我认为min_impurity_decrease可以在某种程度上帮助达成目标。因为微调min_impurity_decrease实际上会修剪决策树。有人能否详细解释一下min_impurity_decrease是什么?
我正在尝试理解scikit learn中的方程式,但我不确定right_impurity和left_impurity的值是多少。
N = 256
N_t = 256
impurity = ??
N_t_R = 242
N_t_L = 14
right_impurity = ??
left_impurity = ??
New_Value = N_t / N * (impurity - ((N_t_R / N_t) * right_impurity)
- ((N_t_L / N_t) * left_impurity))
New_Value
更新2
我们不是按照特定值来修剪,而是根据特定条件进行修剪。 例如, 我们在6/4和5/5处进行分裂,但不在6000/4或5000/5处进行分裂。假设一个值与其节点中相邻的值相比下降了一定百分比,我们将对其进行修剪,而不是按照某个特定值。
11/9
/ \
6/4 5/5
/ \ / \
6/0 0/4 2/2 3/3
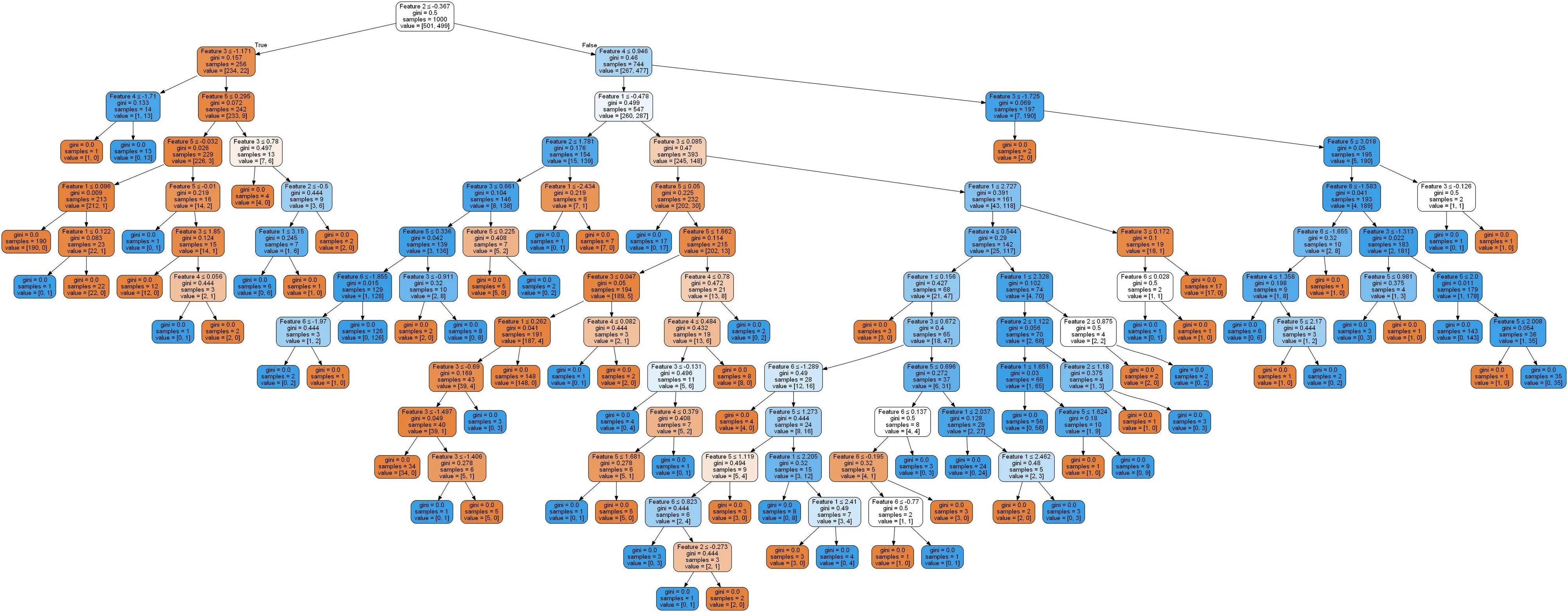
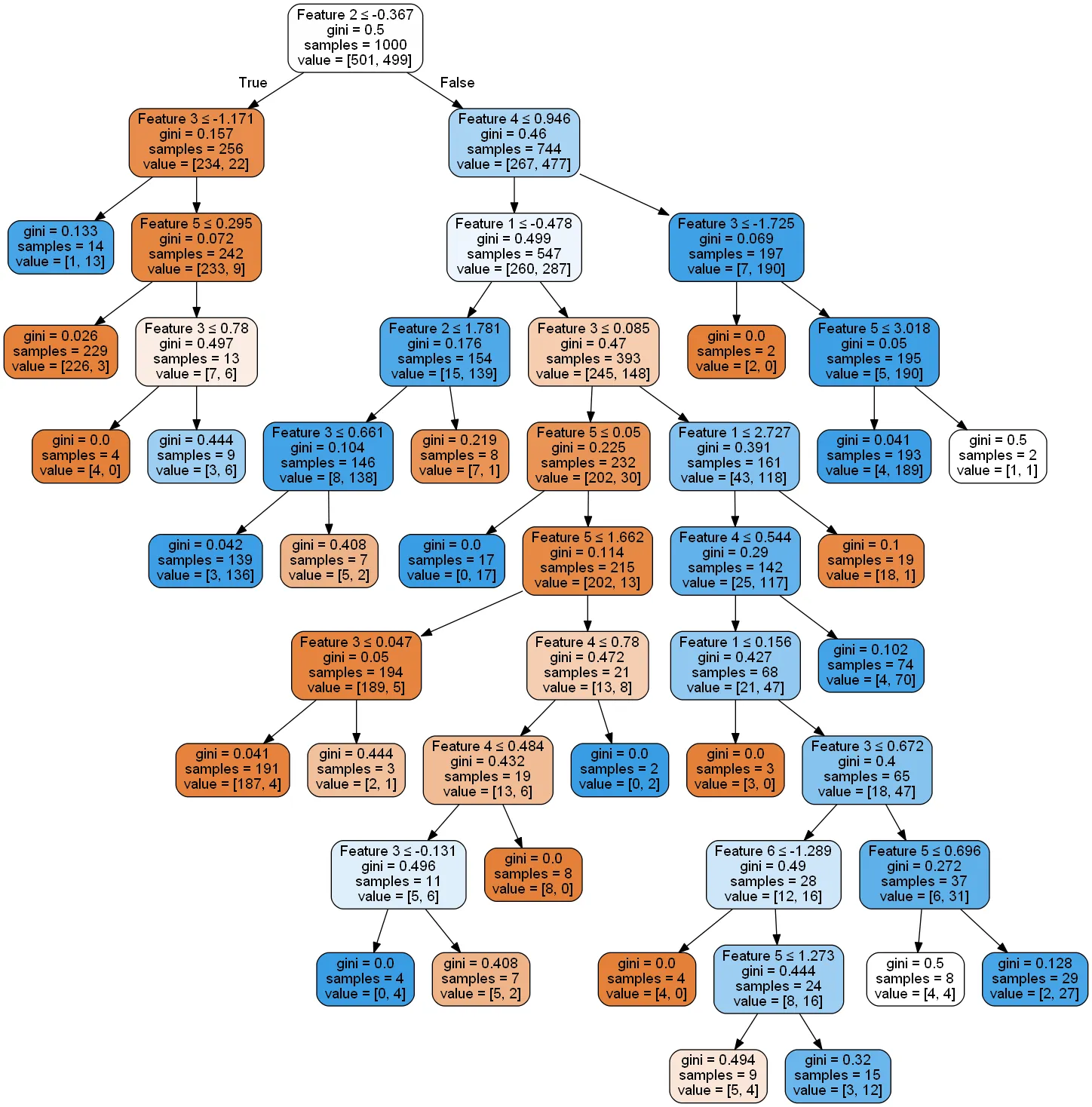
tree_中包含了这棵树。 - SBylemans