我正在优化我的代码,以使图像处理更加高效。我的第一个问题是由于
现在,我的代码在拉普拉斯高斯(LoG)滤波上运行缓慢。我了解到可以使用
进一步阅读后,发现
是否有一种方法可以加快
vision.VideoFileReader和step导致每个帧的打开时间很长。我通过将灰度图像压缩成1个RGB帧中的3个帧来加速代码。这样,我可以使用vid.step()加载1个RGB帧,并准备好处理3个帧。现在,我的代码在拉普拉斯高斯(LoG)滤波上运行缓慢。我了解到可以使用
imfilter函数执行LoG,但它似乎是下一个限制速率的步骤。进一步阅读后,发现
imfilter不是速度最快的选项。显然,MATLAB引入了LoG function,但它是在R2016b中引入的,而我不幸地使用的是R2016a。是否有一种方法可以加快
imfilter的速度,或者有更好的函数用于执行LoG滤波?
我应该调用Python来加速这个过程吗?
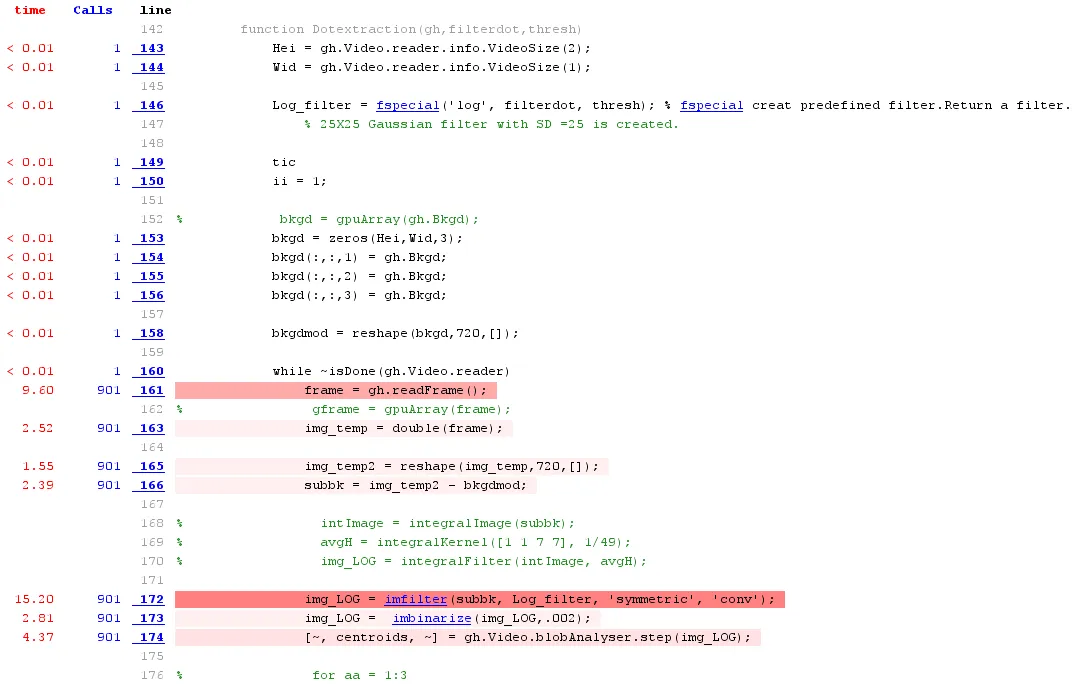
代码:
Hei = gh.Video.reader.info.VideoSize(2);
Wid = gh.Video.reader.info.VideoSize(1);
Log_filter = fspecial('log', filterdot, thresh); % fspecial creat predefined filter.Return a filter.
% 25X25 Gaussian filter with SD =25 is created.
tic
ii = 1;
bkgd = zeros(Hei,Wid,3);
bkgd(:,:,1) = gh.Bkgd;
bkgd(:,:,2) = gh.Bkgd;
bkgd(:,:,3) = gh.Bkgd;
bkgdmod = reshape(bkgd,720,[]);
while ~isDone(gh.Video.reader)
frame = gh.readFrame();
img_temp = double(frame);
img_temp2 = reshape(img_temp,720,[]);
subbk = img_temp2 - bkgdmod;
img_LOG = imfilter(subbk, Log_filter, 'symmetric', 'conv');
img_LOG = imbinarize(img_LOG,.002);
[~, centroids, ~] = gh.Video.blobAnalyser.step(img_LOG);
toc
end
imfilter似乎仍然是我的代码中最快的方法。话虽如此,我认为我没有在我的代码中积极地计算LoG,这就是为什么它更快的原因。我将尝试使用gpuArray来加速处理速度。虽然上次我这样做时,最终减慢了处理速度。:D 我会看看的。再次感谢。 - Hojo.Timberwolffilterdot, thresh中使用的是什么值,但评论显示您使用了sigma=25的25x25滤波器。这确实不是高斯滤波器!事实上,它更接近于均匀滤波器的特征。而且,均匀滤波器(fspecial('average')计算速度非常快。因此,如果您对自己的滤波效果满意,请尝试将其替换为均匀滤波器。 - Cris Luengo