我已经尝试了几周,想要在同一张图上绘制来自一个.csv文件的3组(x, y)数据,但是一无所获。我的数据最初是一个Excel文件,我将它转换为了一个.csv文件,并使用pandas按照以下代码将其读入IPython中:
from pandas import DataFrame, read_csv
import pandas as pd
# define data location
df = read_csv(Location)
df[['LimMag1.3', 'ExpTime1.3', 'LimMag2.0', 'ExpTime2.0', 'LimMag2.5','ExpTime2.5']][:7]
我的数据格式如下:
Type mag1 time1 mag2 time2 mag3 time3
M0 8.87 41.11 8.41 41.11 8.16 65.78;
...
M6 13.95 4392.03 14.41 10395.13 14.66 25988.32
我想在同一张图上绘制 time1 vs mag1、time2 vs mag2 和 time3 vs mag3,但是实际上我得到的是 time.. vs Type 的图像。以下是代码:
df['ExpTime1.3'].plot()
我希望在x轴上显示M0到M6,在y轴上显示'ExpTime1.3'和'LimMag1.3'的关系。如何将这三个数据集合并为同一张图并进行绘制?
如何将M0到M6标签应用到'LimMag..'值(也在x轴上)上?
尝试askewchan的解决方案后,未知原因没有返回任何绘图结果。我发现,如果我将数据框索引(df.index)更改为x轴的值(LimMag1.3),就可以得到ExpTime与LimMag的关系图像: df ['ExpTime1.3'] .plot() 。然而,这似乎意味着我必须通过手动输入所需x轴的所有值来将每个所需的x轴转换为数据框索引,以使其成为数据索引。我的数据非常多,这种方法太慢了,而且我只能一次绘制一个数据集,而我需要在同一张图上绘制每个数据集的所有3个系列。有没有办法解决这个问题?或者有人能提供一个原因和解决方案,解释为什么askewchan的解决方案没有任何绘图结果?
当我尝试代码的第一个版本时,没有产生任何绘图结果,甚至没有空白的图形。每次我输入其中一个ax.plot命令时,都会得到一种输出类型:[<matplotlib.lines.Line2D at 0xb5187b8>],但是当我输入命令plt.show()时就没有反应了。当我在askewchan的第二个解决方法的循环后输入plt.show()时,我会收到一个错误消息,说AttributeError:'function' object has no attribute 'show'。
我对原始代码进行了一些微调,现在可以通过将索引设置为x轴(LimMag1.3),使用代码df['ExpTime1.3'][:7].plot()来绘制ExpTime1.3与LimMag1.3之间的图表,但我无法将另外两组数据绘制在同一个图表上。我会感激您提供进一步的建议。我正在使用Anaconda 1.5.0 (64位)和Windows 7 (64位)上的spyder,python版本是2.7.4。
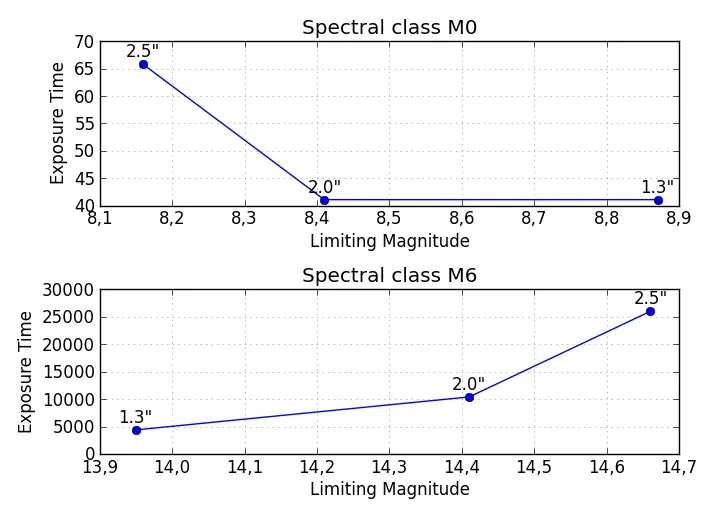
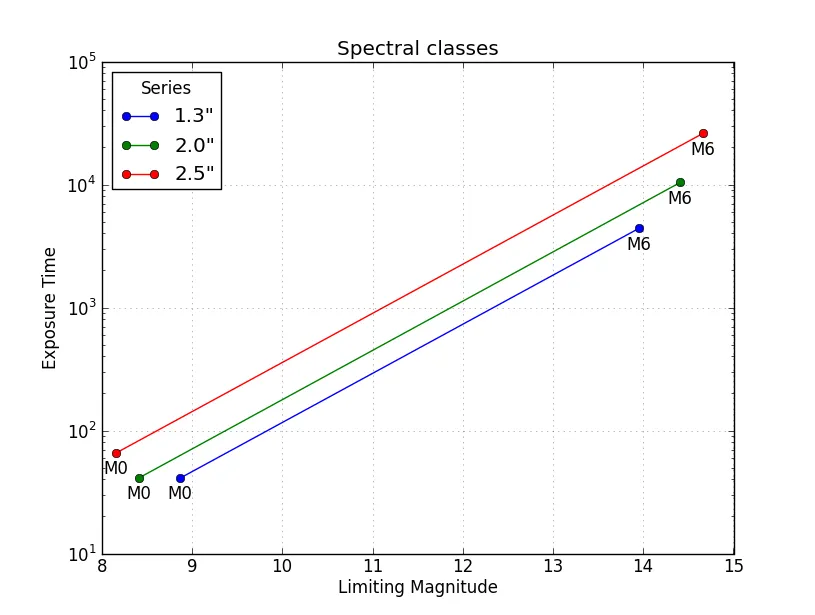
M0-M6作为x轴标签没有实际意义,因为每个M..标签有三个不同的LimMag..值,这意味着每个标签都必须在轴上放置三个不同的位置。这最终看起来会非常混乱,而不是信息丰富。 - soddplt被定义为什么?它不应该是一个“函数”对象。你熟悉使用matplotlib和pyplot吗? - askewchandf中的DataFrame后,在控制台中输入df,复制输出并粘贴到上面的问题中,这样我们就可以看到您的DataFrame是否被正确格式化(M0-M6是索引,而不是单独的列)。 - sodddf.columns,复制输出并粘贴到您的问题上方。 - sodd