您可以使用条件掩码将 AC 以外的任何内容或
np.nan替换为
Other,并使用
groupby.value_counts进行分组,然后使用
unstack和
add_prefix进行格式化。
u = df['status'].where(df['status'].eq("ac")|df['status'].isna(),"Other")
out = (u.groupby(df['ID']).value_counts(dropna=False).unstack(fill_value=0)
.add_prefix("Number_").reset_index().rename_axis(None,axis=1))
或者;
a = pd.Series(np.select([df['status'].eq("ac"),df['status'].isna()],
['acc',np.nan],'other'))
out = (a.groupby(df['ID']).value_counts(dropna=True).unstack(fill_value=0)
.add_prefix("Numnber_").reset_index())
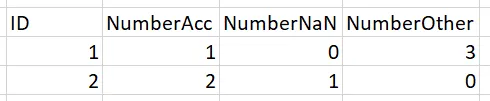
print(out)
ID Number_nan Number_Other Number_ac
0 1 0 3 1
1 2 1 0 2
@Shubham建议采用交叉表格的类似逻辑,如下所示:
u = df['status'].where(df['status'].eq("ac")|df['status'].isna(),"Other")
out = (pd.crosstab(df['ID'],u.fillna("NAN"),dropna=False)
.add_prefix("Number_").rename_axis(None).reset_index())
isin而不是eq来匹配多个值:u = df['status'].where(df['status'].isin(["ac","bc"])|df['status'].isna(),"Other")- ankycrosstab,例如pd.crosstab(df['ID'], df['status'].fillna('NaN'))。 - Shubham Sharma