在NumPy中,命令
我尝试使用SciPy的
根据@frank-yellin的评论,我还尝试了
numpy.corrcoef(X.T)在计算矩阵X中每对列之间的相关性时非常高效。我正在寻找一种类似高效的方法来计算二进制矩阵B中每对列之间的汉明距离。是否有NumPy方法可以适应这个需求?我尝试使用SciPy的
spatial.distance.pdist(X, metric='hamming'),但它比NumPy的成对相关函数慢100倍。根据@frank-yellin的评论,我还尝试了
spatial.distance.pdist(X, metric='cityblock'),但这只加快了计算速度1.7倍 - 这很好,但如果可能的话,我希望能够加快大约100倍的速度。import random
import numpy as np
from scipy import spatial
import time
binary_matrix = np.random.randint(0,2,(1000,1500),dtype = 'int32')
start = time.time()
hamming_with_scipy = spatial.distance.pdist(binary_matrix.T, metric = 'hamming')
end = time.time()
print(f'Hamming takes {end-start} seconds with scipy')
start = time.time()
corr_with_numpy = np.corrcoef(binary_matrix.T)
end = time.time()
print(f'Correlation takes {end-start} seconds with numpy')
输出:
Hamming takes 5.301102876663208 seconds with scipy
Correlation takes 0.03205609321594238 seconds with numpy
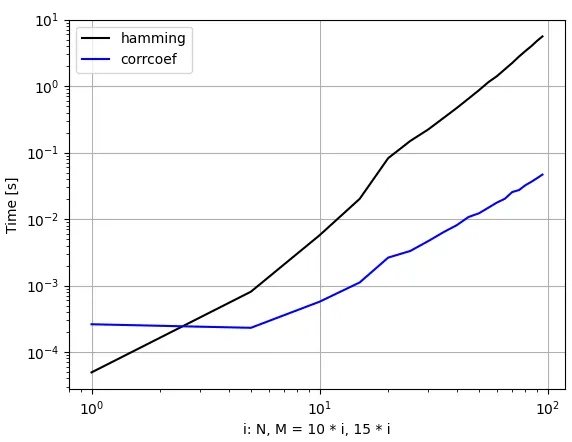
corrcoeff的复杂性显然与pdist不同),即corrcoeff利用了机器的所有核心,而pdist则没有。设置环境变量MKL_NUM_THREADS=1,NUMEXPR_NUM_THREADS=1,OMP_NUM_THREADS=1,以进行有意义的比较。 - undefinedpdist点的方法都取决于后续的处理过程。如果你打算以后查找距离但现在不需要完整的表格,或者想要查找最近的邻居,KDTree数据结构可能会有所帮助。 - undefinedBLAS实现的matmul(实际上是gemm)以一种对CPU缓存友好的方式执行“外积和收缩”。SciPy的实现是“向量化”的,但它对缓存是不敏感的,因此受到RAM速度的限制(通常会减慢100倍)。如果你真的_需要_更快的速度,你应该了解一下对缓存友好的算法,或者从一个好的实现开始并进行适应。你可以在这里找到一个实现:https://akkadia.org/drepper/cpumemory.pdf - undefined