在使用groupby('name')函数并对另一列使用mean()函数后,我得到了这样的Series。
name
383 3.000000
663 1.000000
726 1.000000
737 9.000000
833 8.166667
请问有人能告诉我如何筛选掉平均值为1.000000的行吗?谢谢并非常感谢您的帮助。
In [5]:
import pandas as pd
test = {
383: 3.000000,
663: 1.000000,
726: 1.000000,
737: 9.000000,
833: 8.166667
}
s = pd.Series(test)
s = s[s != 1]
s
Out[0]:
383 3.000000
737 9.000000
833 8.166667
dtype: float64
s并在表达式中使用两次)。不过这只适用于pandas 0.18及以上版本。 - IanS从pandas 0.18+版本开始,可以按以下方式对系列进行过滤
test = {
383: 3.000000,
663: 1.000000,
726: 1.000000,
737: 9.000000,
833: 8.166667
}
pd.Series(test).where(lambda x : x!=1).dropna()
结账: http://pandas.pydata.org/pandas-docs/version/0.18.1/whatsnew.html#method-chaininng-improvements
numpy对底层数组进行切片重构。请参见下面的计时。mask = s.values != 1
pd.Series(s.values[mask], s.index[mask])
0
383 3.000000
737 9.000000
833 8.166667
dtype: float64
天真的时序
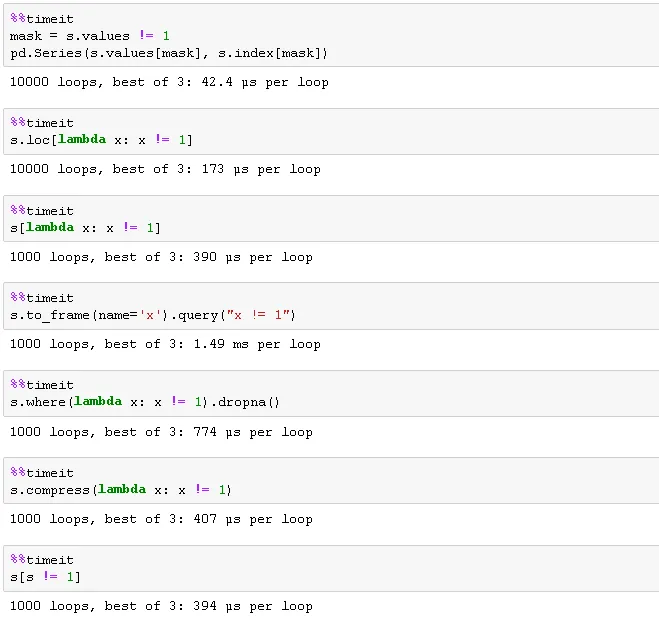
另一种方法是先将数据转换为DataFrame,然后使用query方法(假设您已安装了numexpr):
import pandas as pd
test = {
383: 3.000000,
663: 1.000000,
726: 1.000000,
737: 9.000000,
833: 8.166667
}
s = pd.Series(test)
s.to_frame(name='x').query("x != 1")
compress函数:test = pd.Series({
383: 3.000000,
663: 1.000000,
726: 1.000000,
737: 9.000000,
833: 8.166667
})
test.compress(lambda x: x != 1)
# 383 3.000000
# 737 9.000000
# 833 8.166667
# dtype: float64
pandas版本0.24.0以后,pandas.Series.compress已被弃用。 - ipj在我的情况下,我有一个pandas Series,其中值是字符元组:
Out[67]
0 (H, H, H, H)
1 (H, H, H, T)
2 (H, H, T, H)
3 (H, H, T, T)
4 (H, T, H, H)
apply。我的条件是“查找所有恰好具有一个'H'的元组”。series_of_tuples[series_of_tuples.apply(lambda x: x.count('H')==1)]
我承认它不是“可链接”的(即请注意我重复使用了series_of_tuples两次;您必须将任何临时序列存储到变量中,以便可以在其上调用apply(...))。
除了.apply(...)之外,可能还有其他方法可以逐个元素地生成布尔索引。
许多其他答案(包括被接受的答案)使用可链接函数,例如:
.compress().where().loc[][]这些函数接受可调用对象(lambda),应用于Series,而不是这些系列中的各个值!
因此,当我尝试使用上述条件/可调用对象/lambda和任何可链接函数(如.loc[])时,我的元组系列表现出奇怪的行为:
series_of_tuples.loc[lambda x: x.count('H')==1]
产生了以下错误:
KeyError: 'Level H must be same as name (None)'
我感到非常困惑,但似乎是使用了 Series.count series_of_tuples.count(...) 函数,而这不是我想要的。
我承认另一种数据结构可能更好:
这将创建一系列字符串(即通过将元组连接在一起来连接元组中的字符形成单个字符串)
series_of_tuples.apply(''.join)
这样,我就可以使用可链接的 Series.str.count 函数。
series_of_tuples.apply(''.join).str.count('H')==1