我有一个名为df的示例数据集,其中阶段时间是到达目的地所需天数:
id stage1_time stage_1_to_2_time stage_2_time stage_2_to_3_time stage3_time
a 10 30 40 30 70
b 30
c 15 30 45
d
我编写了以下脚本,以获取stage1_time与CDF的散点图:
我编写了如下脚本,用于得到stage1_time与累积分布函数(CDF)的散点图:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
dict = {'id': id, 'stage_1_time': [10, 30, 15, None], 'stage_1_to_2_time': [30, None, 30, None], 'stage_2_time' : [40, None, 45, None],'stage_2_to_3_time' : [30, None, None, None],'stage_3_time' : [70, None, None, None]}
df = pd.DataFrame(dict)
#create eCDF function
def ecdf(df):
n = len(df)
x = np.sort(df)
y = np.arange(1.0, n+1) / n
return x, y
def generate_scatter_plot(df):
x, y = ecdf(df)
plt.plot(x, y, marker='.', linestyle='none')
plt.axvline(x.mean(), color='gray', linestyle='dashed', linewidth=2) #Add mean
x_m = int(x.mean())
y_m = stats.percentileofscore(df.as_matrix(), x.mean())/100.0
plt.annotate('(%s,%s)' % (x_m,int(y_m*100)) , xy=(x_m,y_m), xytext=(10,-5), textcoords='offset points')
percentiles= np.array([0,25,50,75,100])
x_p = np.percentile(df, percentiles)
y_p = percentiles/100.0
plt.plot(x_p, y_p, marker='D', color='red', linestyle='none') # Overlay quartiles
for x,y in zip(x_p, y_p):
plt.annotate('%s' % int(x), xy=(x,y), xytext=(10,-5), textcoords='offset points')
#Data to plot
stage1_time = df['stage_1_time'].dropna().sort_values()
#Scatter Plot
stage1_time_scatter = generate_scatter_plot(pd.DataFrame({"df" : stage1_time.as_matrix()}))
plt.title('Scatter Plot of Days to Stage1')
plt.xlabel('Days to Stage1')
plt.ylabel('Cumulative Probability')
plt.legend(('Days to Stage1', "Mean", 'Quartiles'), loc='lower right')
plt.margins(0.02)
plt.show()
输出:
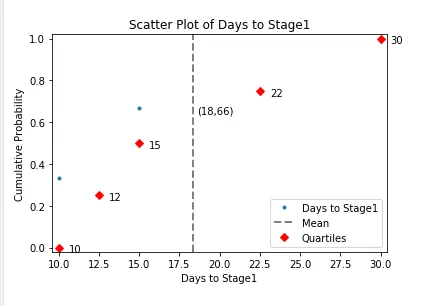
目前我已经将到达stage1的所有人花费的天数绘制成了累积概率图,但是我想要实现的是:当我绘制散点图时,该图有三种颜色:那些到达stage1并停留在那里的人,那些进入stage2的人和那些进入stage3的人。我还想在图表中显示数据的计数:stage1中的数量,stage2中的数量和stage3中的数量。
请问有人能帮我实现吗?
顺便说一下,我想将此作为基础,以便我还可以创建一个关于stage2_time的图表,其中到达stage_3的人会被突出显示为不同的颜色。
generate_scatter_plot函数中,你可以设置多个阶段。对于图例,你可以在generate_scatter_plot中编辑或添加一个列表。 - Aurelia_B