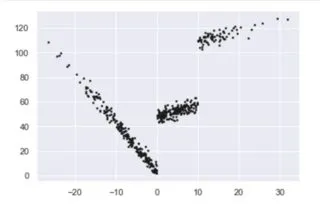
我试图创建一个分段线性回归来最小化均方差(MSE),然后直接使用线性回归。这个方法应该使用动态规划来计算不同分段大小和组合,以实现整体MSE的最小化。我认为算法运行时间复杂度为O(n²),我想知道是否有优化到O(nLogN)的方法?
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn import linear_model
import pandas as pd
import matplotlib.pyplot as plt
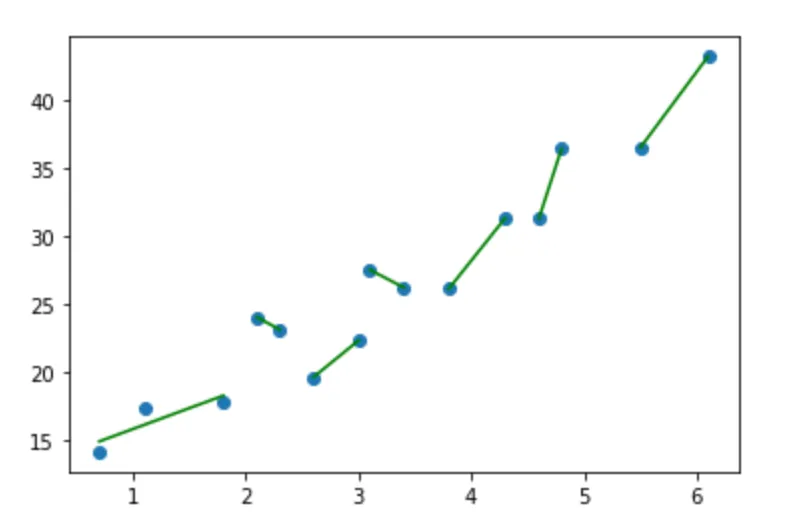
x = [3.4, 1.8, 4.6, 2.3, 3.1, 5.5, 0.7, 3.0, 2.6, 4.3, 2.1, 1.1, 6.1, 4.8,3.8]
y = [26.2, 17.8, 31.3, 23.1, 27.5, 36.5, 14.1, 22.3, 19.6, 31.3, 24.0, 17.3, 43.2, 36.4, 26.1]
dataset = np.dstack((x,y))
dataset = dataset[0]
d_arg = np.argsort(dataset[:,0])
dataset = dataset[d_arg]
def calc_error(dataset):
lr_model = linear_model.LinearRegression()
x = pd.DataFrame(dataset[:,0])
y = pd.DataFrame(dataset[:,1])
lr_model.fit(x,y)
predictions = lr_model.predict(x)
mse = mean_squared_error(y, predictions)
return mse
#n is the number of points , m is the number of groups, k is the minimum number of points in a group
#(15,5,3)returns 【【3,3,3,3,3】】
#(15,5,2) returns [[2,4,3,3,3],[3,2,4,2,4],[4,2,3,3,3]....]
def all_combination(n,m,k):
result = []
if n < k*m:
print('There are not enough elements to split.')
return
combination_bottom = [k for q in range(m)]
#add greedy algorithm here?
if n == k*m:
result.append(combination_bottom.copy())
else:
combination_now = [combination_bottom.copy()]
j = k*m+1
while j < n+1:
combination_last = combination_now.copy()
combination_now = []
for x in combination_last:
for i in range (0, m):
combination_new = x.copy()
combination_new[i] = combination_new[i]+1
combination_now.append(combination_new.copy())
j += 1
else:
for x in combination_last:
for i in range (0, m):
combination_new = x.copy()
combination_new[i] = combination_new[i]+1
if combination_new not in result:
result.append(combination_new.copy())
return result #2-d list
def calc_sum_error(dataset,cb):#cb = combination
mse_sum = 0
for n in range(0,len(cb)):
if n == 0:
low = 0
high = cb[0]
else:
low = 0
for i in range(0,n):
low += cb[i]
high = low + cb[n]
mse_sum += calc_error(dataset[low:high])
return mse_sum
#k is the number of points as a group
def best_piecewise(dataset,k):
lenth = len(dataset)
max_split = lenth // k
min_mse = calc_error(dataset)
split_cb = []
all_cb = []
for i in range(2, max_split+1):
split_result = all_combination(lenth, i, k)
all_cb += split_result
for cb in split_result:
tmp_mse = calc_sum_error(dataset,cb)
if tmp_mse < min_mse:
min_mse = tmp_mse
split_cb = cb
return min_mse, split_cb, all_cb
min_mse, split_cb, all_cb = best_piecewise(dataset, 2)
print('The best split of the data is '+str(split_cb))
print('The minimum MSE value is '+str(min_mse))
x = np.array(dataset[:,0])
y = np.array(dataset[:,1])
plt.plot(x,y,"o")
for n in range(0,len(split_cb)):
if n == 0:
low = 0
high = split_cb[n]
else:
low = 0
for i in range(0,n):
low += split_cb[i]
high = low + split_cb[n]
x_tmp = pd.DataFrame(dataset[low:high,0])
y_tmp = pd.DataFrame(dataset[low:high,1])
lr_model = linear_model.LinearRegression()
lr_model.fit(x_tmp,y_tmp)
y_predict = lr_model.predict(x_tmp)
plt.plot(x_tmp, y_predict, 'g-')
plt.show()
如果有任何部分没有表述清楚,请告诉我。
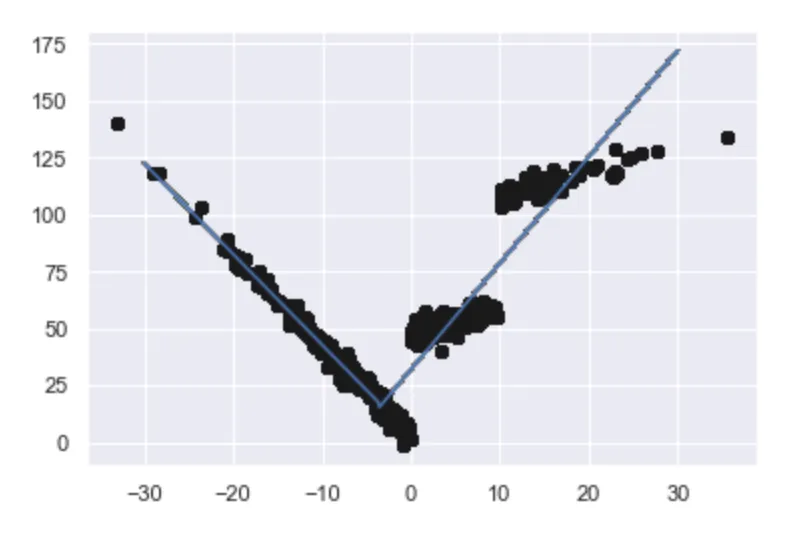
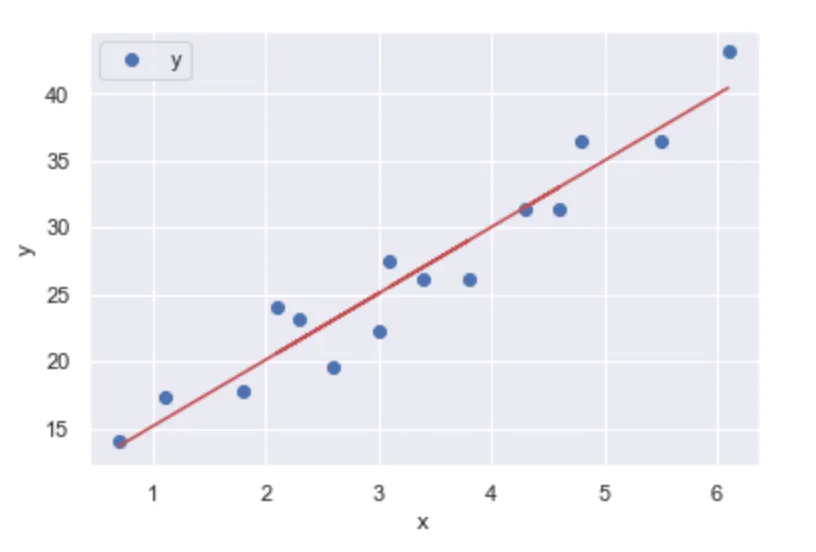 这个右侧的线性回归为我们提供了完整x值范围内的y值,并且(可能)会继续下去。函数的连续性正是我们所追求的。在另一个例子中,您可以尝试使用任意数量的工具,包括决策树回归器,但您要么得到类似脆弱的结果,要么得到不符合期望的结果。然后呢?因为它“错误”而抛弃它?因为“计算机说什么就是什么”而接受它?两种都一样糟糕。
这个右侧的线性回归为我们提供了完整x值范围内的y值,并且(可能)会继续下去。函数的连续性正是我们所追求的。在另一个例子中,您可以尝试使用任意数量的工具,包括决策树回归器,但您要么得到类似脆弱的结果,要么得到不符合期望的结果。然后呢?因为它“错误”而抛弃它?因为“计算机说什么就是什么”而接受它?两种都一样糟糕。