我正在尝试将数据集中的字符串转换为浮点数类型。以下是一些背景信息:
import pandas as pd
import numpy as np
import xlrd
file_location = "/Users/sekr2/Desktop/Jari/Leistungen/leistungen2_2017.xlsx"
workbook = xlrd.open_workbook(file_location)
sheet = workbook.sheet_by_index(0)
df = pd.read_excel("/Users/.../bla.xlsx")
df.head()
Leistungserbringer Anzahl Leistung AL TL TaxW Taxpunkte
0 McGregor Sarah 12 'Konsilium' 147.28 87.47 KVG 234.75
1 McGregor Sarah 12 'Grundberatung' 47.00 67.47 KVG 114.47
2 McGregor Sarah 12 'Extra 5min' 87.28 87.47 KVG 174.75
3 McGregor Sarah 12 'Respirator' 147.28 102.01 KVG 249.29
4 McGregor Sarah 12 'Besuch' 167.28 87.45 KVG 254.73
为了继续进行,我需要找到一种创建新列的方法:
df['Leistungswert'] = df['Taxpunkte'] * df['Anzahl'] * df['TaxW'].每个条目中的TaxW显示字符串'KVG'。 根据数据,我知道'KVG'= 0.89。 我试图将该字符串转换为浮点数,但却遇到了困境。 因为这段代码将用于进一步输入,所以不能只创建一个新列并指定浮点类型。在列TaxW中,大约有7个不同的条目,其值都不同。
感谢提供有关此问题的所有信息。
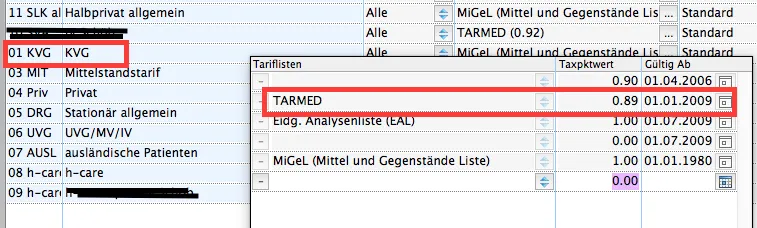
'KVG' = 0.89吗? - IanS