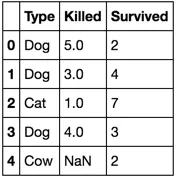
假设我有这个表格
Type | Killed | Survived
Dog 5 2
Dog 3 4
Cat 1 7
Dog nan 3
cow nan 2
在[Type] = Dog中,Killed的一个值缺失。
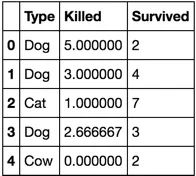
我想要在[Type] = Dog中用[Killed]的平均数来填充缺失值。
我的代码如下:
- 搜索平均数
df[df['Type'] == 'Dog'].mean().round()
这将给出平均值(约为2.25)
- 填充平均数(这是问题开始的地方)
df.loc[(df['Type'] == 'Dog') & (df['Killed'])].fillna(2.25, inplace = True)
代码运行了,但值没有被填充,NaN值仍然存在。
我的问题是,如何根据[Type] = Dog在[Killed]中填充平均数。
2.25? - shivsn8/3。 - shivsn