考虑以下 Python 代码,在其中,对一个预先转置的矩阵进行乘法运算比对一个非转置的矩阵进行乘法运算具有更快的执行时间。
import numpy as np
import time
# Generate random matrix
matrix_size = 1000
matrix = np.random.rand(matrix_size, matrix_size)
# Transpose the matrix
transposed_matrix = np.transpose(matrix)
# Multiply non-transposed matrix
start = time.time()
result1 = np.matmul(matrix, matrix)
end = time.time()
execution_time1 = end - start
# Multiply pre-transposed matrix
start = time.time()
result2 = np.matmul(transposed_matrix, transposed_matrix)
end = time.time()
execution_time2 = end - start
print("Execution time (non-transposed):", execution_time1)
print("Execution time (pre-transposed):", execution_time2)
令人惊讶的是,乘以预转置矩阵更快。也许有人会认为乘法的顺序不应该显著影响性能,但似乎确实有差别。
为什么处理预转置矩阵会导致比未转置矩阵更快的执行时间?是否有任何潜在原因或优化可以解释这种行为?
更新
我已经考虑了关于cache的评论,并且在每次循环中生成新的矩阵:
import numpy as np
import time
import matplotlib.pyplot as plt
# Generate random matrices
matrix_size = 3000
# Variables to store execution times
execution_times1 = []
execution_times2 = []
# Perform matrix multiplication A @ B^T and measure execution time for 50 iterations
num_iterations = 50
for _ in range(num_iterations):
matrix_a = np.random.rand(matrix_size, matrix_size)
start = time.time()
result1 = np.matmul(matrix_a, matrix_a)
end = time.time()
execution_times1.append(end - start)
# Perform matrix multiplication A @ B and measure execution time for 50 iterations
for _ in range(num_iterations):
matrix_b = np.random.rand(matrix_size, matrix_size)
start = time.time()
result2 = np.matmul(matrix_b, matrix_b.T)
end = time.time()
execution_times2.append(end - start)
# Print average execution times
avg_execution_time1 = np.mean(execution_times1)
avg_execution_time2 = np.mean(execution_times2)
#print("Average execution time (A @ B^T):", avg_execution_time1)
#print("Average execution time (A @ B):", avg_execution_time2)
# Plot the execution times
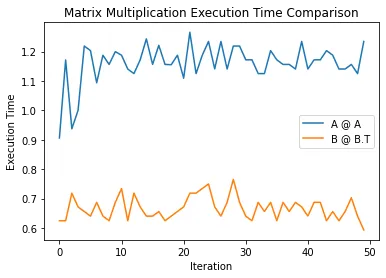
plt.plot(range(num_iterations), execution_times1, label='A @ A')
plt.plot(range(num_iterations), execution_times2, label='B @ B.T')
plt.xlabel('Iteration')
plt.ylabel('Execution Time')
plt.title('Matrix Multiplication Execution Time Comparison')
plt.legend()
plt.show()
# Display BLAS configuration
np.show_config()
结果:
blas_mkl_info:
libraries = ['mkl_rt']
library_dirs = ['C:/Users/User/anaconda3\\Library\\lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['C:/Users/User/anaconda3\\Library\\include']
blas_opt_info:
libraries = ['mkl_rt']
library_dirs = ['C:/Users/User/anaconda3\\Library\\lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['C:/Users/User/anaconda3\\Library\\include']
lapack_mkl_info:
libraries = ['mkl_rt']
library_dirs = ['C:/Users/User/anaconda3\\Library\\lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['C:/Users/User/anaconda3\\Library\\include']
lapack_opt_info:
libraries = ['mkl_rt']
library_dirs = ['C:/Users/User/anaconda3\\Library\\lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['C:/Users/User/anaconda3\\Library\\include']
Supported SIMD extensions in this NumPy install:
baseline = SSE,SSE2,SSE3
found = SSSE3,SSE41,POPCNT,SSE42,AVX,F16C,FMA3,AVX2
not found = AVX512F,AVX512CD,AVX512_SKX,AVX512_CLX,AVX512_CNL
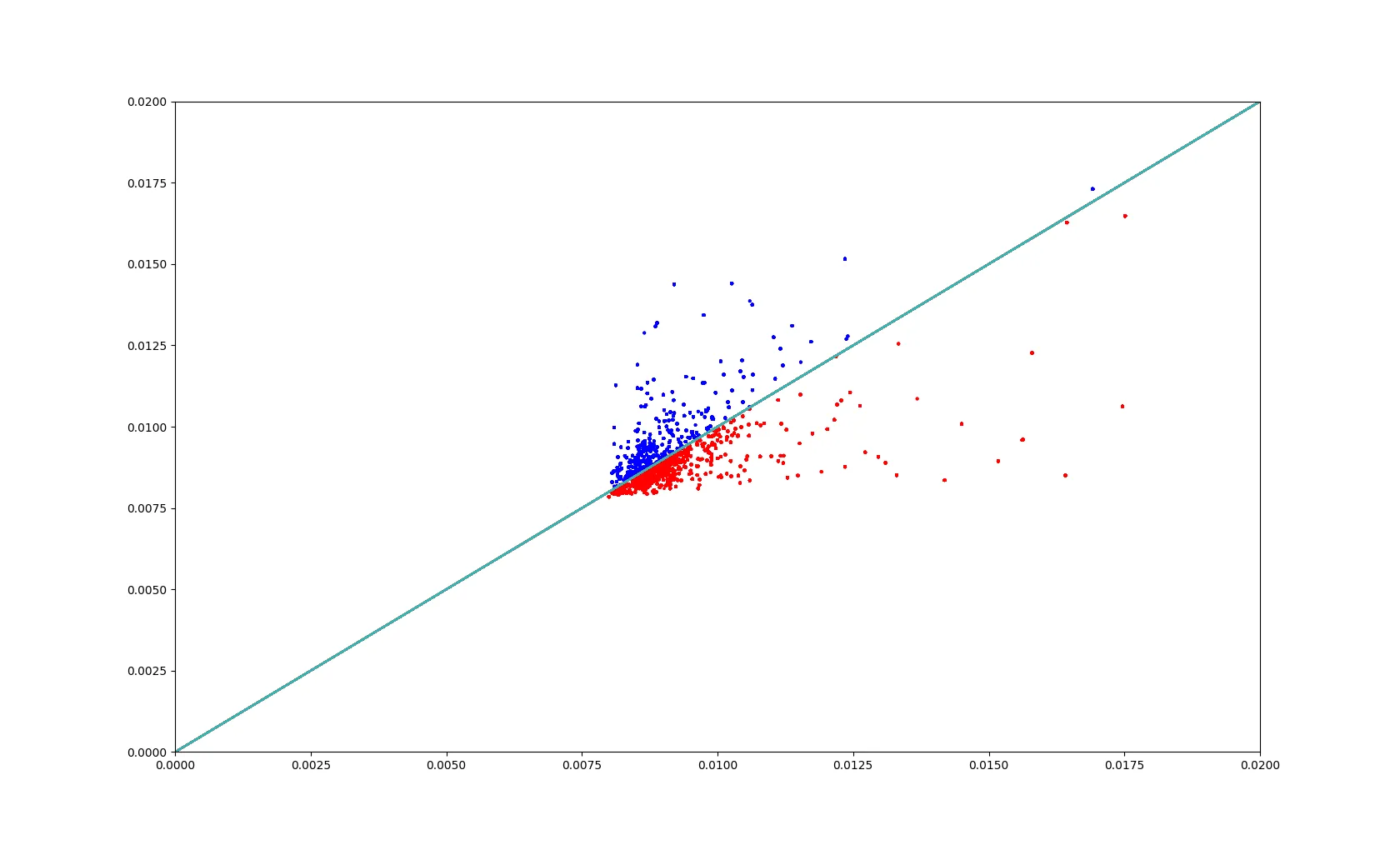
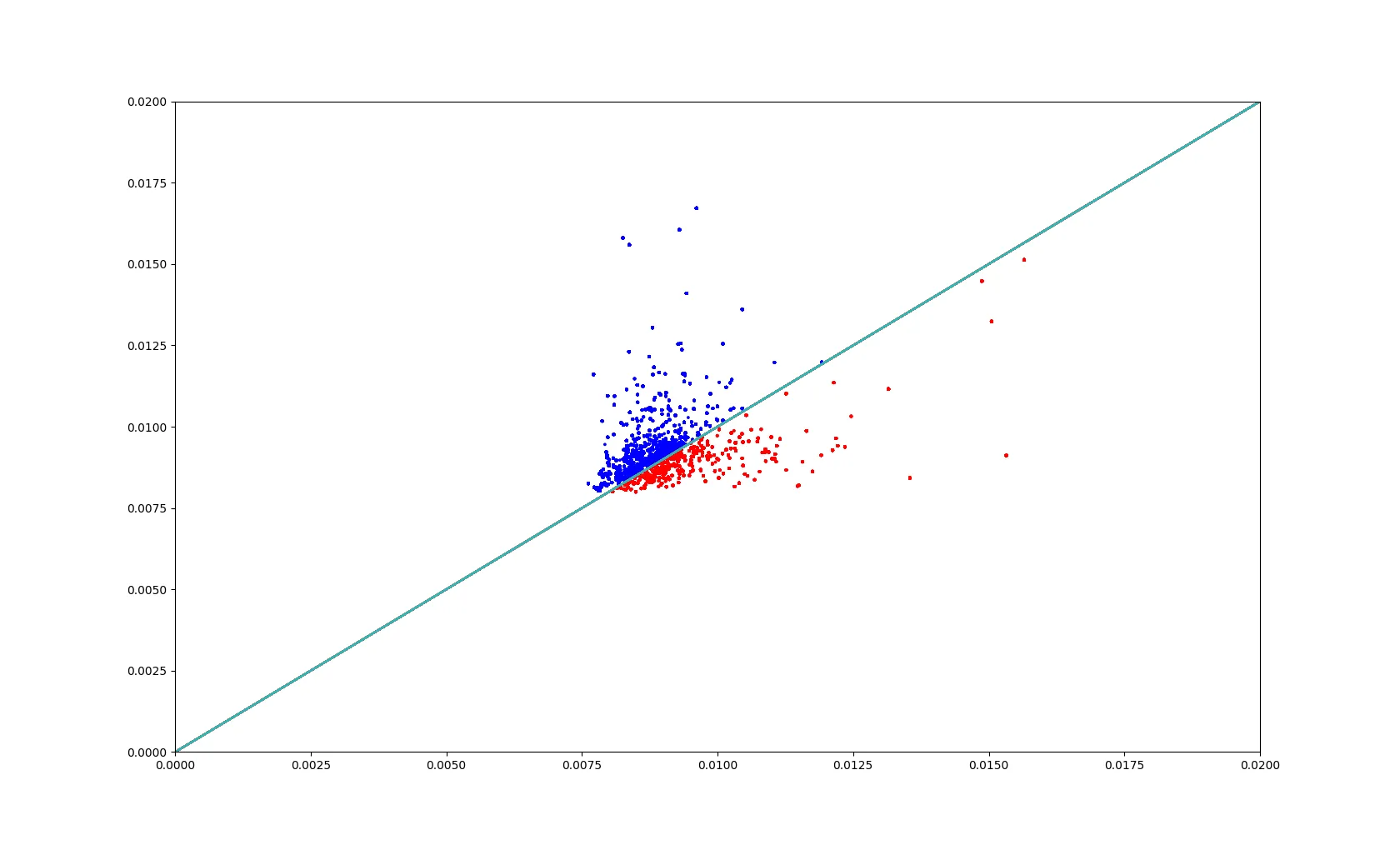
np.matmul(matrix_b, matrix_b.T)的对称性,它可以比np.matmul(matrix_a, matrix_a)快近一倍。 - max9111np.matmul(matrix_b, matrix_b.T)的结果是对称的,通过利用这个特性,它可以比np.matmul(matrix_a, matrix_a)快近两倍。 - max9111np.matmul(matrix_b, matrix_b.T)的结果是对称的,通过利用这种行为,它可以比np.matmul(matrix_a, matrix_a)快近两倍。 - undefined