我的问题是“如何为学习问题设计核函数?” 在支持向量机和核机器的书籍中,作者提供了一些核函数的例子(例如多项式核、高斯核和文本核),但他们要么只提供结果的图片而不具体说明核函数,要么笼统地声称“可以构建有效的核函数”。我对为新问题设计核函数的流程很感兴趣。
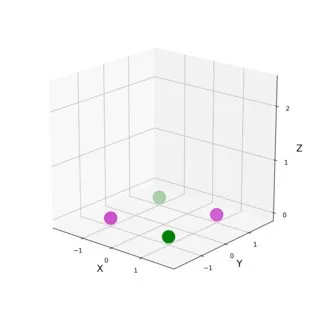
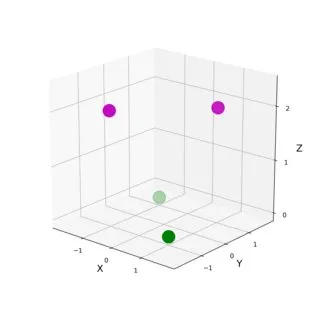
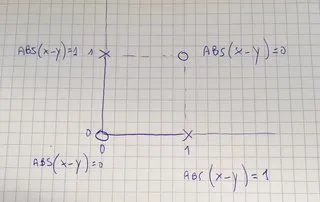
最简单的例子可能是学习异或运算,这是一个在实数平面上嵌入的最小非线性数据集(4个点)。如何设计一个自然(且非平凡)的核函数来线性分离这些数据?
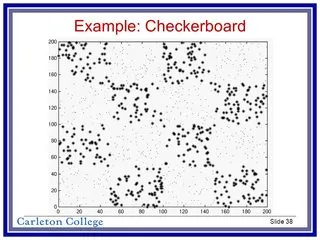
作为一个更复杂的例子(见Cristianini,《SVM入门》第6.2节),如何设计一个核函数来学习棋盘图案?Cristianini称这张图片是“使用高斯核导出的”,但他使用了多个核函数,并以未指定的方式进行组合和修改。
如果这个问题过于宽泛,无法在此处回答,那么我希望得到一个构建这样一个核函数的参考资料,尽管我更喜欢这个例子相对简单。
最简单的例子可能是学习异或运算,这是一个在实数平面上嵌入的最小非线性数据集(4个点)。如何设计一个自然(且非平凡)的核函数来线性分离这些数据?
作为一个更复杂的例子(见Cristianini,《SVM入门》第6.2节),如何设计一个核函数来学习棋盘图案?Cristianini称这张图片是“使用高斯核导出的”,但他使用了多个核函数,并以未指定的方式进行组合和修改。
如果这个问题过于宽泛,无法在此处回答,那么我希望得到一个构建这样一个核函数的参考资料,尽管我更喜欢这个例子相对简单。