在阅读了这篇StackOverflow上的帖子(最优化部分) 之后,我想知道为什么条件移动不容易受到分支预测失败的影响。在这篇AMD的PDF文件中,他们也声称了条件移动的性能优势。但是为什么呢?我没有看出来。在评估那个汇编指令的时候,前面CMP指令的结果还不知道。
为什么条件移动不容易受到分支预测失败的影响?
106
- Martijn Courteaux
5
12顺带一提,你可能想知道,在我的Intel Core2和Core-i7 CPU上的经验中,cmov并不总是能提升性能。在我的测试中,只要分支预测率高于约99%,分支本身就更好。这听起来可能很高,但在Intel的分支预测器中相当普遍。特别是在循环内部的分支情况下,比如迭代1000次的分支,在第999次做了些不同的事情。这种情况总是使用条件跳转比使用cmov更有效率。 - jstine
1PDF链接目前需要授权。 - leewz
对于C++编译器来说,它们是相同的:请参见附图。 - Nikolai Trandafil
1@NikolaiTrandafil:这完全取决于您选择的编译器,启用的编译标志以及目标ISA。 - Martijn Courteaux
相关:CMOVcc是否被视为分支指令? - 不是,它是一个ALU选择操作。答案包括一些有关性能权衡的详细信息链接。 - Peter Cordes
5个回答
85
预测错误的分支代价高昂
如果一切顺利(如果处理器不必等待先前的指令或内存中依赖数据的到达),现代处理器通常每个周期执行一到三条指令。
上述说法在紧密循环中通常成立,但这并不应该让你忽视另一个可能阻止指令在其周期到来时执行的附加依赖关系: 为了执行一条指令,处理器必须在15-20个周期之前开始获取和解码它。
当处理器遇到一个分支时应该怎么做呢?同时获取和解码两个目标是不可行的(如果跟随更多分支,则必须并行获取指数级路径)。因此,处理器只会获取和解码其中一个分支,具有推测性。
这就是为什么预测错误的分支代价高昂:它们会花费15-20个周期,而这些周期通常因为高效的指令管道而无法察觉。
条件移动从未非常昂贵
条件移动不需要预测,因此永远不会有这种惩罚。它具有数据依赖关系,与普通指令相同。实际上,条件移动具有比普通指令更多的数据依赖关系,因为数据依赖关系包括“条件真”和“条件假”的情况。在将r1移动到r2的指令之后,r2的内容似乎依赖于r2的先前值和r1。良好预测的条件分支允许处理器推断出更准确的依赖关系。但是,如果需要等待,数据依赖关系通常需要花费一到两个周期才能到达。
请注意,从内存到寄存器的条件移动有时可能是一个危险的赌注:如果条件不是将从内存中读取的值分配给寄存器,则你白白等待内存。但是指令集中提供的条件移动指令通常是从寄存器到寄存器,避免了程序员犯这种错误。
- Pascal Cuoq
7
1除了第一句话,我同意你写的所有内容(或者至少对我来说看起来是可以接受的)。你能详细说明一下CPU每个周期将执行三个汇编指令的那部分吗? - Martijn Courteaux
4一般现代台式机处理器的所有流水线阶段都能够处理大约3条指令,最佳情况下每个周期可以实现3条指令/周期的吞吐量。例如,解码阶段可以每个周期解码16个字节的指令:通常是3条指令。还有足够多的执行单元,可以在一个周期内处理三条独立的指令。详情请参见http://www.agner.org/optimize/microarchitecture.pdf(顺便说一下,这是一个很好的参考资料)。 - Pascal Cuoq
例如第79页:“管道的其余吞吐量通常为每个时钟周期4条指令”(但你几乎从不会获得理论上的每个周期4条指令。即使是3条指令,也只有在算法允许并需要手写、手动对齐的特定处理器模型的代码时才能实现)。 - Pascal Cuoq
所以,它可以解码4条指令,但在同一周期内处理2或3条指令,这取决于算法的运行情况? - Martijn Courteaux
@PeterCordes -
adc 相对较小的不同之处在于 cmov 可以接受多个标志输入,因此对于单独重命名的标志,它需要使用合并 uop 强制相关标志在一起,或者接受 2 个标志输入(就像最近芯片上的 jcc 似乎所做的那样)。 - BeeOnRope显示剩余2条评论
58
这一切都与指令流水线有关。请记住,现代CPU会在流水线中运行它们的指令,当执行流程被CPU预测时,流水线能够显著提升性能。
cmov
add eax, ebx
cmp eax, 0x10
cmovne ebx, ecx
add eax, ecx
在评估ASM指令的那一刻,先前的CMP指令的结果还不确定。
也许如此,但是CPU仍然知道在cmov之后紧跟着执行的指令,无论cmp和cmov指令的结果如何。 因此,下一个指令可以安全地提前获取/解码,这在分支语句中并非如此。
即使在cmov执行之前,下一条指令也可以执行(在我的示例中,这是安全的)
branch
add eax, ebx
cmp eax, 0x10
je .skip
mov ebx, ecx
.skip:
add eax, ecx
je .skip时,它必须选择继续预取/解码指令的方式:1)从下一条指令,或2)从跳转目标。CPU会猜测这个前向条件分支不会发生,所以下一条指令mov ebx, ecx将进入流水线。几个周期后,
je .skip被执行并且跳转被执行。哦,该死!我们的流水线现在保存着一些永远不应该被执行的随机垃圾。CPU必须清空所有缓存的指令,并从.skip:重新开始。这就是错误预测分支的性能惩罚,而使用
cmov则永远不会发生,因为它不会改变执行流程。- Martin
1
5我可以理解这可能是带有操作码、目的地和来源的Intel语法,但如果您明确提及汇编标准,那就太好了。 - Zan Lynx
20
确实,结果可能尚未知道,但如果其他情况允许(特别是依赖链),CPU可以重新排序并执行cmov后面的指令。由于没有涉及分支,这些指令必须在任何情况下进行评估。
考虑以下示例:
cmoveq edx, eax
add ecx, ebx
mov eax, [ecx]
cmov 指令后的两个指令不依赖于 cmov 的结果,因此它们可以在 cmov 本身等待期间执行(这称为乱序执行)。 即使无法执行,它们仍然可以被提取和解码。
一个分支版本可能是:
jne skip
mov edx, eax
skip:
add ecx, ebx
mov eax, [ecx]
问题在于控制流正在更改,而CPU并不足够聪明,无法意识到如果分支预测错误为taken,它可以“插入”跳过的mov指令 - 而是丢弃分支后执行的所有指令,并从头开始重新执行。这就是惩罚的来源。
- Jester
1
2我可以看出这很可能是Intel语法,包含操作码、目标和源,但如果您能明确提及您的汇编标准,那就太好了。 - Zan Lynx
6
请阅读以下内容。使用Fog+Intel,只需搜索CMOV。
Linus Torvald对CMOV的评价(2007年左右)
Agner Fog的微体系结构比较
Intel® 64和IA-32体系结构优化参考手册
简而言之,正确预测是“免费”的,而条件分支错误可能会在Haswell上耗费14-20个时钟周期。然而,CMOV永远不是免费的。尽管如此,我认为现在的CMOV比Torvalds抱怨时要好得多。没有一个通用的答案可以适用于所有处理器的所有时间。
- Olsonist
2
3不,
cmov 仍然是一种数据依赖,因此可能会创建循环传递的依赖链,而分支预测会隐藏它。Intel Broadwell/Skylake将其解码为单个uop而不是2个(Haswell和早期版本),因此现在稍微便宜了一些。Sandybridge及更高版本的uop缓存意味着多uop指令的解码吞吐量惩罚通常不是一个问题。但它并没有改变数据依赖和控制依赖之间的根本差异。此外,x86 cmov 仍然没有带立即操作数的形式,因此 x = x<3 ? x : 3 的实现仍然很笨拙。 - Peter Cordes另一个可能感兴趣的链接:https://gcc.gnu.org/bugzilla/show_bug.cgi?id=56309 - Max Barraclough
1
我有一张来自 [Peter Puschner et al.] 幻灯片的插图,它解释了如何将代码转换为单一路径,并加速执行。
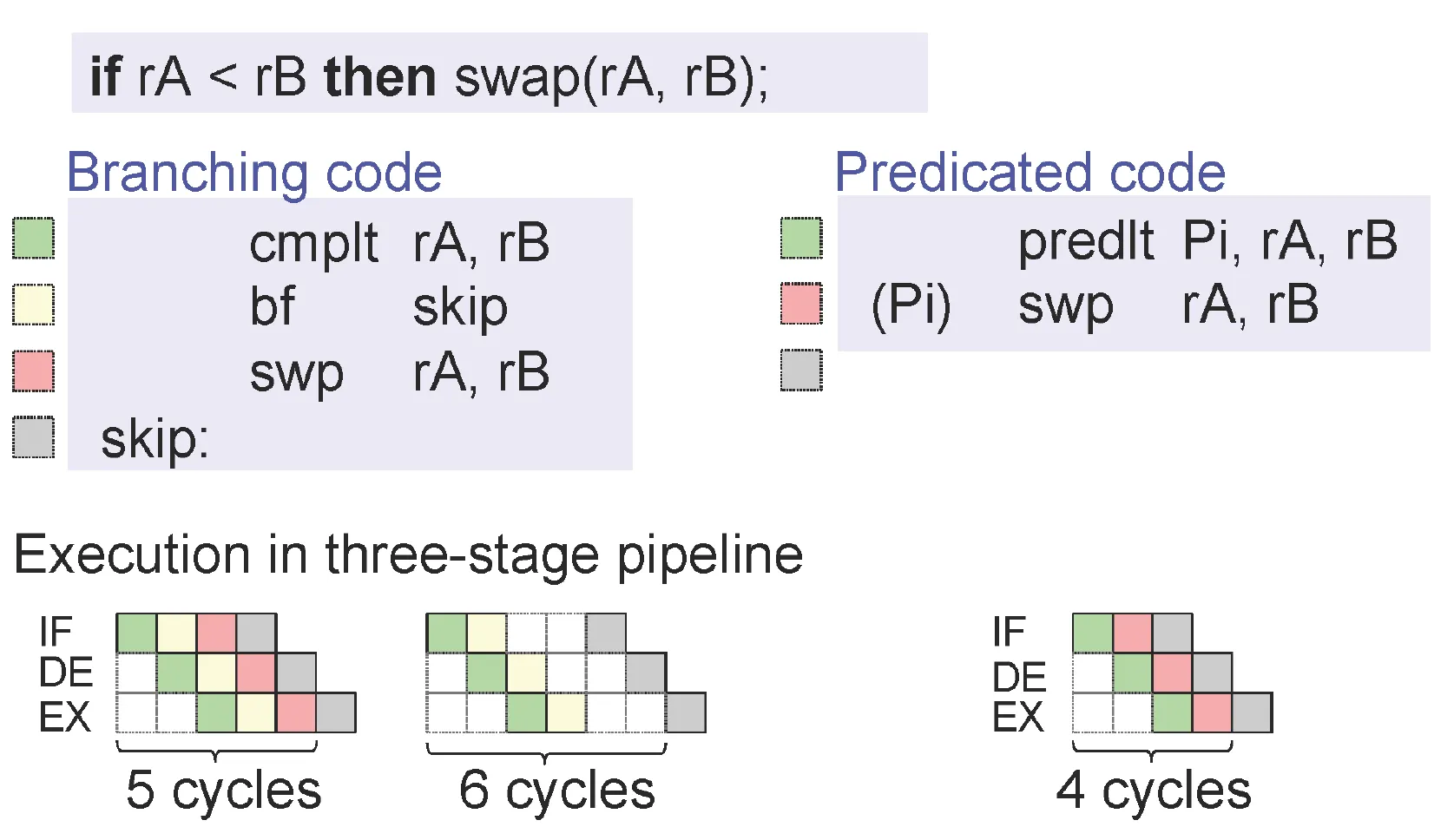
- COLD ICE
1
1一种比较和谓词下一个指令会很好,但实际架构通常需要3个指令来进行预测序列。(除了ARM 32位,如果它有一个交换指令,那么就可以使用cmp / swplt。)无论如何,现代CPU通常不是从已跳转的分支中产生气泡,而是从错误预测中产生气泡: https://dev59.com/iWgu5IYBdhLWcg3wkH6P. 在高吞吐量代码中,正确预测的已跳转分支可以减少解码/前端带宽。 - Peter Cordes
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接