如何预测分支的简要历史:
当曾祖母在编程 时,还没有预测和预取,后来她开始在执行当前指令的同时预取下一条指令。大多数情况下这是正确的,在大多数情况下每条指令的时钟周期都可以提高一个,否则就不会有任何损失。这已经有了平均34%(59%-9%,H&P AQA p.81)的误判率。
时,还没有预测和预取,后来她开始在执行当前指令的同时预取下一条指令。大多数情况下这是正确的,在大多数情况下每条指令的时钟周期都可以提高一个,否则就不会有任何损失。这已经有了平均34%(59%-9%,H&P AQA p.81)的误判率。
当祖母在编程 时。
时。
问题在于CPU速度越来越快,向流水线中添加了一个解码阶段,使其变为获取 -> 解码 -> 执行 -> 写回。如果分支是向后或向前的,并且分别被采取和不被采取,则每5条指令之间会丢失2个提取。快速研究表明,大多数条件向后分支都是循环,大多数都被采取,而大多数向前分支则不被采取,因为它们大多是坏情况。通过分析,我们可以将其降至3%-24%。
动态分支预测器与饱和计数器
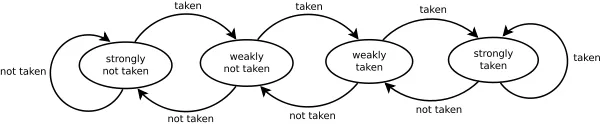
的出现使程序员

的生活更加轻松。观察到大多数分支做与上次相同的事情,有一个低位地址的计数器列表告诉分支是否被采取,分支目标缓冲器提供要获取的地址。在这个本地预测器上,它将误判率降低到1%-18%。
这很好,但是某些分支取决于以前其他分支的操作。因此,如果我们有最后分支采取或不采取的历史记录为1和0,那么根据历史记录,我们有2^H个不同的预测器。实际上,历史位与分支较低地址位进行异或运算,使用与先前版本相同的数组。
这样做的好处是预测器可以快速学习模式,缺点是如果没有模式,分支将覆盖前面分支的位。好处超过缺点,因为本地性比不在当前(内部)循环中的分支更重要。这个全局预测器将误判率提高到1%-11%。
这很好,但在某些情况下,本地预测器能够击败全局预测器,因此我们需要两者兼备。通过将本地分支历史记录与地址进行异或运算,可以改善本地分支预测,使其成为一个二级预测器,而不是全局分支历史。为每个分支添加第三个饱和计数器来计算哪个正确,我们可以在它们之间进行选择。这个竞技预测器相对于全局预测器将误判率提高了约1%。
现在你的情况是100个分支中的一个朝另一个方向。
让我们来看一下本地两级预测器,当我们进入第一个情况时,这些分支的最后H个分支一直朝着同一个方向,假设是taken,使得所有历史都是1,因此分支预测器将选择本地预测表中的单个条目,并且会被饱和为taken。这意味着在这种情况下它将在所有情况下造成误判,而下一次调用分支将很可能被正确预测(除了别名到分支表条目)。因此,不能使用本地分支预测器,因为需要100位长的历史记录将需要2 ^ 100大的预测器。
也许全局预测器能够捕捉到这种情况,在过去99次中,分支已经被执行,因此最后99个预测器将根据最后H个分支的不同行为进行更新,使它们预测分支将被执行。因此,如果最后H个分支与当前分支具有独立的行为,则全局分支预测表中的所有条目都将预测分支将被执行,从而导致误判。
但是,如果以前的分支组合,例如第3、第7和第12个分支,都采取了行动,以便在采取/不采取这些分支的正确组合时,它将预示相反的行为,则此组合的分支预测条目将正确预测分支的行为。问题在于,如果您只偶尔在程序运行时看到此分支条目及其别名分支的行为更新,则可能无法正确预测。
假设全局分支行为实际上基于先前分支的模式预测了正确的结果。那么你很可能会被锦标赛预测器误导,它说本地预测器总是正确的,而本地预测器对于你的情况总是会错误地预测。
注1:“总是”应该带着一小粒沙子看待,因为其他分支可能会污染您的分支表条目,并将其别名分支与相同的条目。设计师已经尝试通过具有8K个不同条目并创造性地重新排列分支的较低地址的位来减少这种可能性。
注2:其他方案可能能够解决这个问题,但不太可能,因为这是100中的1。