我正在尝试理解这篇论文,该论文解释了如何训练神经网络玩乒乓球游戏。
https://cloud.github.com/downloads/inf0-warri0r/neural_pong/README.pdf
我最近开始学习神经网络,并了解反向传播的概念。在这篇论文中,反向传播被用来训练神经网络。
这个神经网络有五个输入神经元:
这个神经网络有五个输入神经元:
- 球的x坐标(bx)
- 球的y坐标(by)
- x方向上的球速度(bvx)
- y方向上的球速度(bvy)
- 挡板的位置(py)。
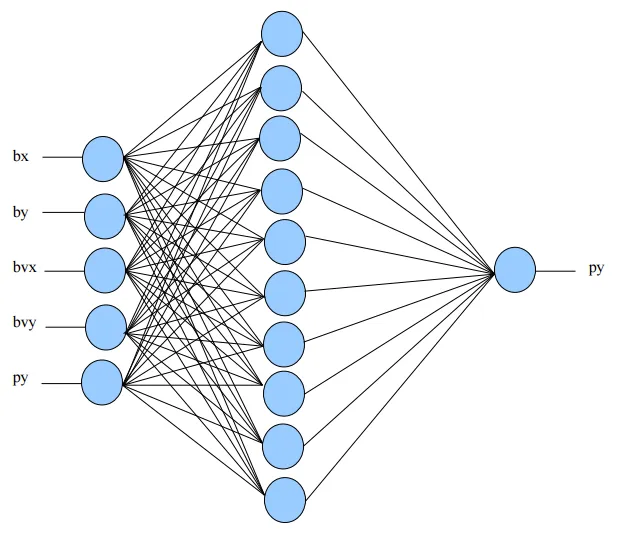
从这一点开始,我有一些疑问需要澄清。
由于反向传播是一种监督学习方法,因此它应该有一些期望的输出,我们从中迭代地减去当前输出以找到输出中的误差并计算梯度下降。
现在我不明白的是,在这种情况下期望的输出是什么。它可以是球撞击墙壁的位置与挡板位置之间的距离,我们应该将其保持为零吗?
我知道控制挡板将被硬编码为与球同步移动,但是我们如何在训练时随机移动另一个挡板?我们应该在输入“py”中给出什么值?
在游戏的哪个时刻应该提供所有五个输入bx、by、bvx、bvy和py?当球撞击墙壁时,我们应该提供这些输入并执行一次神经网络迭代吗?