我试图识别每个数字的图片。我已经除去了除了数字之外的所有内容,以便除了数字放置在图片上不同以外,几乎没有噪音。我使用Neuroph的图像识别GUI,并对训练有一些问题。
似乎我用于图片的分辨率越大,训练效果就越差。这是为什么?我的训练集中有100张图片。每个数字有10张。这可能太少了吗?为什么无论我做什么,每次训练都只会收敛到一些数字通常在2-3之间的总网络错误。
这里是其中一个训练的图片
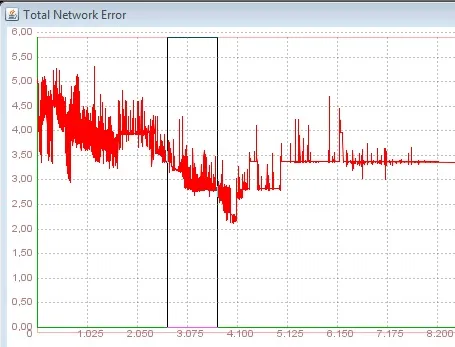
它并没有学到很多东西
我试图识别每个数字的图片。我已经除去了除了数字之外的所有内容,以便除了数字放置在图片上不同以外,几乎没有噪音。我使用Neuroph的图像识别GUI,并对训练有一些问题。
似乎我用于图片的分辨率越大,训练效果就越差。这是为什么?我的训练集中有100张图片。每个数字有10张。这可能太少了吗?为什么无论我做什么,每次训练都只会收敛到一些数字通常在2-3之间的总网络错误。
这里是其中一个训练的图片
它并没有学到很多东西
信息量呈指数级增长!
当您提供更高分辨率的图像时,会提供额外的信息需要进行评估。
如果您的分辨率是10x10px,那么每个图像将有100个像素,您的每个数字有10个图像,也就是每个数字有1000个像素。
现在,如果您将分辨率提高到20x20px,那么每个图像将有400个像素,或者每个数字将有4000个像素。
换句话说:增加分辨率会导致每个数字要评估的像素数量呈指数级增长。
添加更多(不必要的)像素会增加错误的可能性:
通常,在机器学习中,图片被削减到最少(无论是大小还是颜色),以尽可能减少错误的空间。当您有更多的像素时,算法可能会学习到与实际图像形状完全无关的像素信息。