我目前正在尝试让人工神经网络玩一个视频游戏,并希望从这里美妙的社区中获得一些帮助。
我选择了《暗黑破坏神2》。游戏是实时的,以等距视角进行游戏,玩家控制一个单一的角色,摄像机以其为中心。
为了使事情具体化,任务是让您的角色获得x点经验值,而不使其健康值降至0,其中通过杀死怪物获得经验点。以下是游戏玩法的示例:
所有这些信息都必须以某种方式教给网络。我无法想象如何训练这个东西。我的唯一想法是有一个单独的程序从屏幕中提取游戏中天生好/坏的东西(例如健康,黄金,经验),然后在强化学习过程中使用该统计数据。我认为这将是答案的一部分,但我认为这还不够;从原始视觉输入到目标导向行为有太多抽象层次,以至于如此有限的反馈无法在我的有生之年内训练出一个网络。
所以,我的问题是:你能想到其他方法来训练网络完成至少部分任务吗?最好不要制作数千个标记示例。
只是为了更好的方向:我正在寻找一些其他的强化学习来源和/或在这种情况下提取有用信息的任何无监督方法。如果您能想到一种方法,可以获得游戏世界中的标记数据,而无需手动标记它,则可以使用受监督的算法。
更新(04/27/12):
我选择了《暗黑破坏神2》。游戏是实时的,以等距视角进行游戏,玩家控制一个单一的角色,摄像机以其为中心。
为了使事情具体化,任务是让您的角色获得x点经验值,而不使其健康值降至0,其中通过杀死怪物获得经验点。以下是游戏玩法的示例:
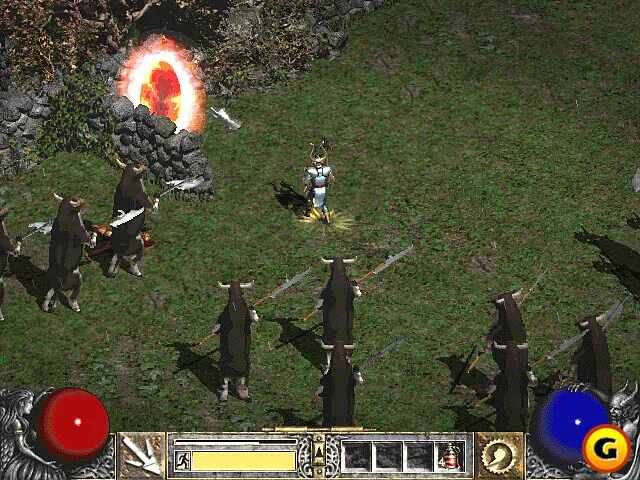
所有这些信息都必须以某种方式教给网络。我无法想象如何训练这个东西。我的唯一想法是有一个单独的程序从屏幕中提取游戏中天生好/坏的东西(例如健康,黄金,经验),然后在强化学习过程中使用该统计数据。我认为这将是答案的一部分,但我认为这还不够;从原始视觉输入到目标导向行为有太多抽象层次,以至于如此有限的反馈无法在我的有生之年内训练出一个网络。
所以,我的问题是:你能想到其他方法来训练网络完成至少部分任务吗?最好不要制作数千个标记示例。
只是为了更好的方向:我正在寻找一些其他的强化学习来源和/或在这种情况下提取有用信息的任何无监督方法。如果您能想到一种方法,可以获得游戏世界中的标记数据,而无需手动标记它,则可以使用受监督的算法。
更新(04/27/12):
奇怪的是,我仍在继续这项工作,并似乎正在取得进展。让ANN控制器正常工作的最大秘密是使用最先进的适用于任务的ANN架构。因此,在微调时间差反向传播(即使用标准前馈ANN进行强化学习)之前,我使用了一个由分解有条件限制玻尔兹曼机组成的深度置信网络进行了无监督训练(使用我玩游戏的视频)。
尽管如此,我仍在寻找更有价值的信息,特别是关于实时动作选择问题以及如何为ANN处理编码彩色图像方面的问题:-)
更新(10/21/15):
我刚想起来我曾经问过这个问题,并且我认为我应该提到这不再是一个疯狂的想法。自从我上次更新以来,DeepMind发表了他们的自然论文,关于如何让神经网络通过视觉输入玩Atari游戏。实际上,唯一阻止我使用他们的架构来玩Diablo 2的是缺乏对底层游戏引擎的访问权限。将其渲染到屏幕上,然后将其重定向到网络中进行训练所需的时间太长。因此,我们可能不会很快看到这种机器人玩Diablo 2,但只是因为它将玩一些开源或具有API访问渲染目标的东西。(也许是Quake?)