我编写了一段代码,它读取两个字符串,然后比较它们是否含有相似的单词。接着会生成一个包含数据的表格。
我的问题是它总是被分成两部分。我需要纠正这个问题,以便将其合并到HTML中。感谢您提前的任何帮助!:)
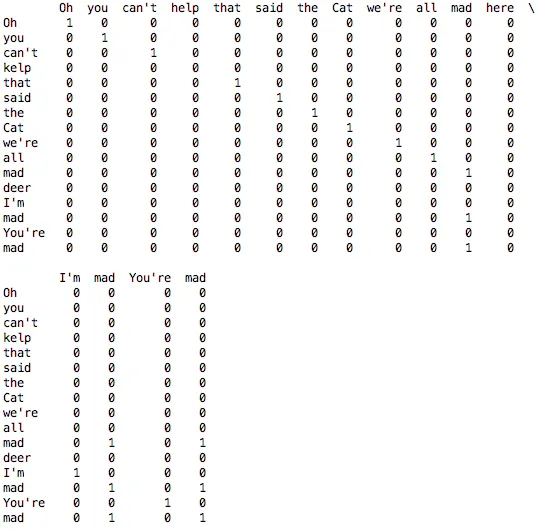
我还尝试了仅打印顶部行。

完整代码:
import string
from os import path
import pandas as pd
pd.set_option('display.max_columns', None) #prevents trailing elipses
pd.set_option('display.max_rows', None)
import os.path
BASE = os.path.dirname(os.path.abspath(__file__))
file1 = open(os.path.join(BASE, "samp.txt"))
sampInput=file1.read().replace('\n', '')
file2 = open(os.path.join(BASE, "ref.txt"))
refInput=file2.read().replace('\n', '')
sampArray = [word.strip(string.punctuation) for word in sampInput.split()]
refArray = [word.strip(string.punctuation) for word in refInput.split()]
out=pd.DataFrame(index=sampArray,columns=refArray)
for i in range(0, out.shape[0]): #from 0 to total number of rows
for word in refArray: #for each word in the samplearray
df1 = out.iloc[0, 0:16].copy()
top = out.ix[:1, :17]
out.ix[i,str(word)] = out.index[i].count(str(word))
#print(out)
print(top)
#print(df1)