总结
使用基于循环的单遍复制方法,并用Numba加速,提供了最佳的速度、内存效率和灵活性的整体权衡。
如果条件函数的执行足够快,则两个遍(filter2_nb())可能更快,而且无论如何它们都更节省内存。
此外,对于足够大的输入,改变大小而不是复制(filter_resize_xnb())可以导致更快的执行。
如果数据类型(和条件函数)事先已知并且可以编译,则Cython加速似乎更快。
很可能硬编码条件会导致使用Numba加速产生相当的加速。
在仅基于NumPy的方法中,布尔掩码或整数索引具有可比较的速度,哪一个更快取决于过滤因子,即通过过滤条件的值的部分。
np.fromiter()方法非常慢(在图表中会脱离),但不会产生大型临时对象。
请注意,以下测试旨在为不同的方法提供一些见解,并应该谨慎参考。
最相关的假设是条件可以广播,并且最终计算非常快。
定义
- 使用生成器:
def filter_fromiter(arr, cond):
return np.fromiter((x for x in arr if cond(x)), dtype=arr.dtype)
- 使用布尔掩码:
def filter_mask(arr, cond):
return arr[cond(arr)]
- 使用整数索引:
def filter_idx(arr, cond):
return arr[np.nonzero(cond(arr))]
4a. 使用显式循环,单次遍历并进行最终复制/调整大小
%%cython -c-O3 -c-march=native -a
import numpy as np
cdef long NUM = 1048576
cdef long MAX_VAL = 1048576
cdef long K = 1048576 // 2
cdef int cond_cy(long x, long k=K):
return x < k
cdef size_t _filter_cy(long[:] arr, long[:] result, size_t size):
cdef size_t j = 0
for i in range(size):
if cond_cy(arr[i]):
result[j] = arr[i]
j += 1
return j
def filter_cy(arr):
result = np.empty_like(arr)
new_size = _filter_cy(arr, result, arr.size)
return result[:new_size].copy()
def filter_resize_cy(arr):
result = np.empty_like(arr)
new_size = _filter_cy(arr, result, arr.size)
result.resize(new_size)
return result
import numba as nb
@nb.njit
def cond_nb(x, k=K):
return x < k
@nb.njit
def filter_nb(arr, cond_nb):
result = np.empty_like(arr)
j = 0
for i in range(arr.size):
if cond_nb(arr[i]):
result[j] = arr[i]
j += 1
return result[:j].copy()
@nb.njit
def _filter_out_nb(arr, out, cond_nb):
j = 0
for i in range(arr.size):
if cond_nb(arr[i]):
out[j] = arr[i]
j += 1
return j
def filter_resize_xnb(arr, cond_nb):
result = np.empty_like(arr)
j = _filter_out_nb(arr, result, cond_nb)
result.resize(j, refcheck=False)
return result
- 使用生成器和
np.fromiter()加速Numba
@nb.njit
def filter_gen_nb(arr, cond_nb):
for i in range(arr.size):
if cond_nb(arr[i]):
yield arr[i]
def filter_gen_xnb(arr, cond_nb):
return np.fromiter(filter_gen_nb(arr, cond_nb), dtype=arr.dtype)
4b. 使用显式循环进行两次遍历:一次确定结果的大小,一次实际执行计算
%%cython -c-O3 -c-march=native -a
cdef size_t _filtered_size_cy(long[:] arr, size_t size):
cdef size_t j = 0
for i in range(size):
if cond_cy(arr[i]):
j += 1
return j
def filter2_cy(arr):
cdef size_t new_size = _filtered_size_cy(arr, arr.size)
result = np.empty(new_size, dtype=arr.dtype)
new_size = _filter_cy(arr, result, arr.size)
return result
@nb.njit
def filter2_nb(arr, cond_nb):
j = 0
for i in range(arr.size):
if cond_nb(arr[i]):
j += 1
result = np.empty(j, dtype=arr.dtype)
j = 0
for i in range(arr.size):
if cond_nb(arr[i]):
result[j] = arr[i]
j += 1
return result
计时基准
(生成器-based的filter_fromiter()方法比其他方法慢得多--大约慢两个数量级。
类似(或许稍微更差)的性能可以从列表推导式中预期。
这对于任何使用非加速代码的明确循环都是正确的。)
计时取决于输入数组大小和过滤项的百分比。
随着输入大小的变化而变化
第一个图表说明了随着输入大小变化时的计时(对于~50%的过滤因子--即结果中有50%的元素):
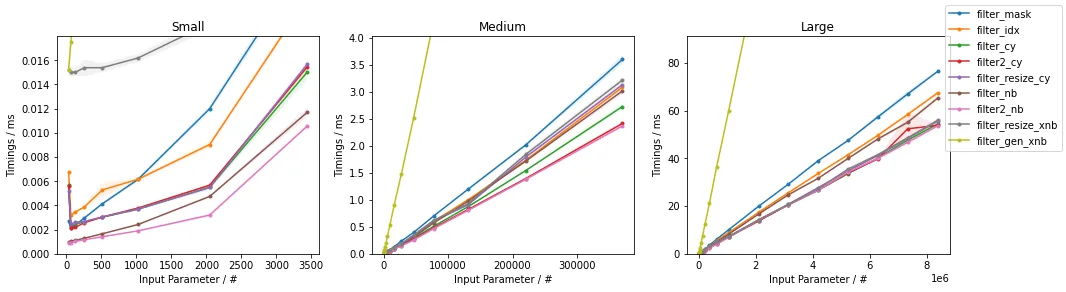
一般来说,使用某种形式的加速明确循环会导致最快的执行,具体取决于输入大小。
在NumPy内部,整数索引方法与布尔蒙版方法基本相同。
使用np.fromiter()(没有预分配)的好处可以通过编写Numba加速生成器来实现,这将比其他方法慢(在一个数量级内),但比纯Python循环快得多。
随填充功能的变化
第二个图表说明了随着通过过滤器的项目数量的变化而变化的时间(对于~100万个元素的固定输入大小):
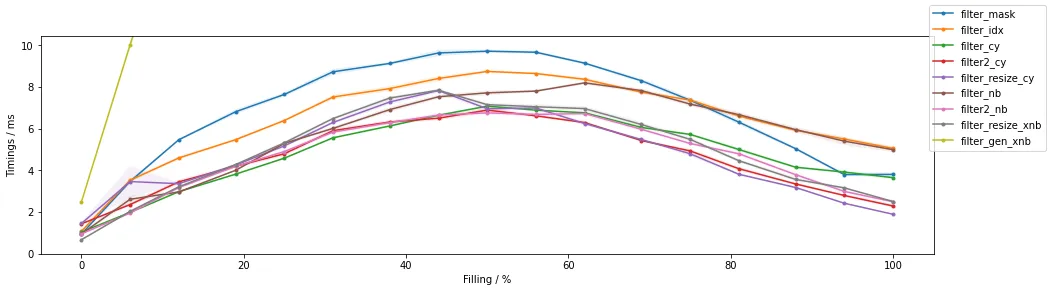
第一项观察是,当接近~50%填充时,所有方法都最慢,并且在填充较少或更多的情况下,它们更快,并且朝向无填充最快(在图表的x轴中表示为过滤掉最高比例的值,通过值的百分比最低)。
同样,在使用某种形式的加速明确循环时,执行速度最快。
在NumPy内部,整数索引和布尔蒙版方法再次基本相同。
(完整代码可在此处查看)
内存考虑
基于生成器的filter_fromiter()方法仅需要最少量的临时存储空间,与输入大小无关。
就内存而言,这是最高效的方法。
此方法可以通过使用Numba加速生成器来有效地加快速度。
在内存效率方面,Cython / Numba双通方法的内存效率相似,因为输出大小在第一次传递期间确定。
这里的警告是,对于这些方法要快,计算条件必须快。
在内存方面,Cython和Numba的单通解决方案需要一个与输入大小相同的临时数组。
因此,它们与两个通道或基于生成器的比起来不太内存有效。
然而,它们与掩码具有类似的渐进临时内存占用量,但常数项通常大于掩码。
布尔掩码解决方案需要一个类型为bool的临时数组,其大小与输入相同,在NumPy中为1字节,因此在典型的64位系统上比NumPy数组默认大小小约8倍。
整数索引解决方案具有与布尔掩码切片相同的要求(在np.nonzero()调用内部),该切片会转换为一系列int(在第二步中,即np.nonzero()的输出中通常是int64)。
因此,第二步具有可变的内存需求,这取决于筛选元素的数量。
备注
- 布尔掩码和整数索引都需要某种形式的条件来生成布尔掩码(或者,作为替代方案,索引列表);在上述实现中,条件是可广播的
- 生成器和Numba加速方法在指定不同的过滤条件时也最灵活
- Numba加速方法要求条件与Numba兼容以便在NoPython模式下访问Numba加速
- Cython解决方案需要指定数据类型才能快速运行,或者额外工作以进行多个类型调度,并且需要额外工作(在此处未探索)以获得与其他方法相同的灵活性
- 对于Numba和Cython,过滤条件可以硬编码,导致微小但明显的速度差异
- 单通解决方案需要额外的代码来处理未使用(但初始分配)的内存。
- NumPy方法不会返回输入的视图,而是返回副本,这是由于高级索引的结果:
arr = np.arange(100)
k = 50
print('`arr[arr > k]` is a copy: ', arr[arr > k].base is None)
print('`arr[np.where(arr > k)]` is a copy: ', arr[np.where(arr > k)].base is None)
print('`arr[:k]` is a copy: ', arr[:k].base is None)
抱歉,我只能以英文回答。
numpy的文档不鼓励仅使用条件来使用numpy.where。numpy.where(condition)(只有一个条件,没有x/y参数)等同于numpy.asarray(condition).nonzero();推荐的方法是直接调用.nonzero(),例如arr[(arr < k).nonzero()]。这样可以正确处理子类,并且运行速度更快。 - ShadowRangerarr[(arr > k).nonzero()]和arr[arr > k]之间的区别吗?在一些简单的测试中它们表现相同。 - AMC