我编写了一个分类器(高斯混合模型)来对五种人类行为进行分类。对于每个观测值,分类器计算属于聚类的后验概率。
我想评估我的系统参数化阈值的性能,阈值从0到100。对于每个阈值值,对于每个观察值,如果属于一个聚类的概率大于阈值,则接受分类器的结果,否则舍弃。
对于每个阈值值,我计算真正,真负,假正,假负的数量。
然后我计算两个函数:敏感度和特异度,如下:
我想评估我的系统参数化阈值的性能,阈值从0到100。对于每个阈值值,对于每个观察值,如果属于一个聚类的概率大于阈值,则接受分类器的结果,否则舍弃。
对于每个阈值值,我计算真正,真负,假正,假负的数量。
然后我计算两个函数:敏感度和特异度,如下:
sensitivity = TP/(TP+FN);
specificity=TN/(TN+FP);
在Matlab中:
plot(1-specificity,sensitivity);
我需要绘制ROC曲线,但结果与我的预期不符。
这是一个函数图,它显示了在更改某个操作的阈值时丢弃、错误、正确、灵敏度和特异性的函数。
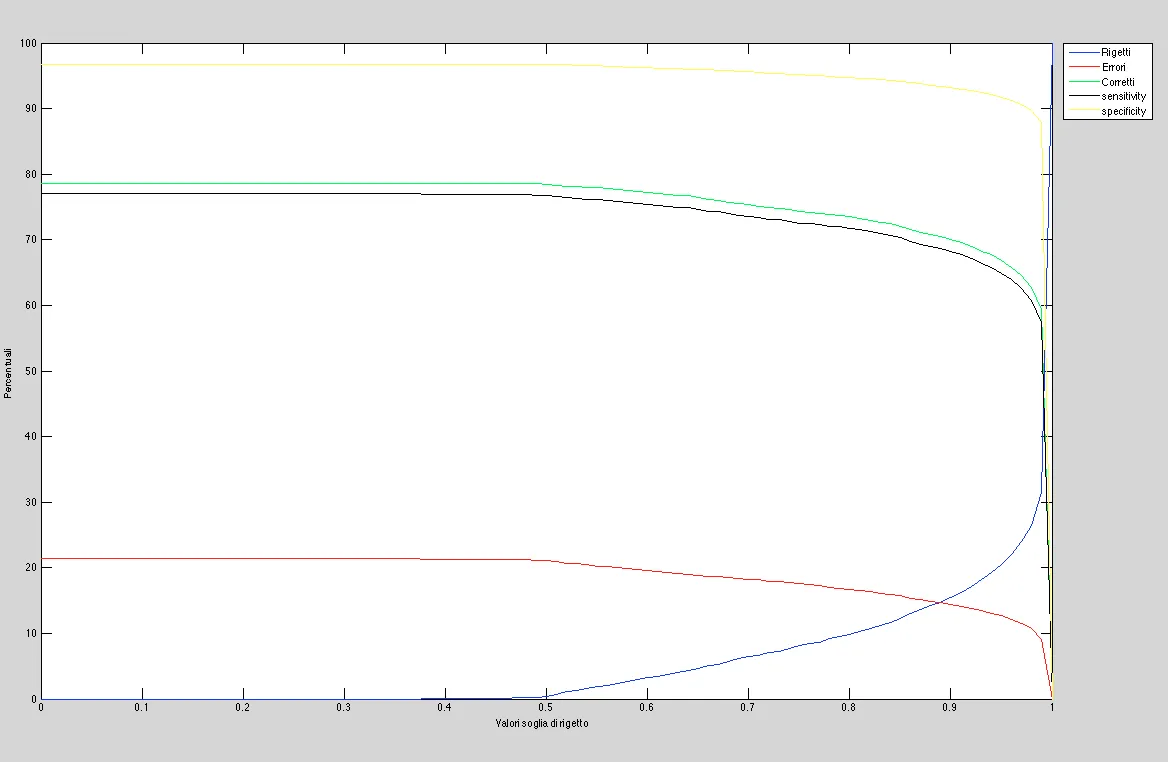
这是一个操作的ROC曲线图像
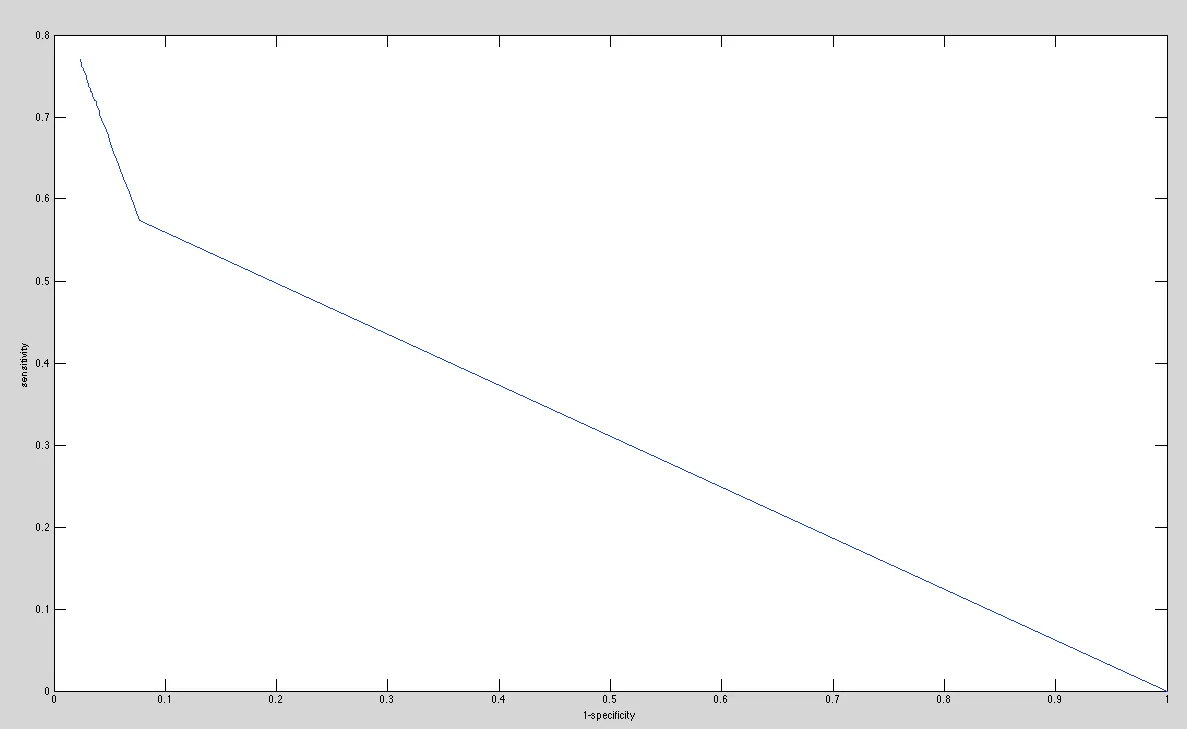
这是同一操作的ROC曲线图像
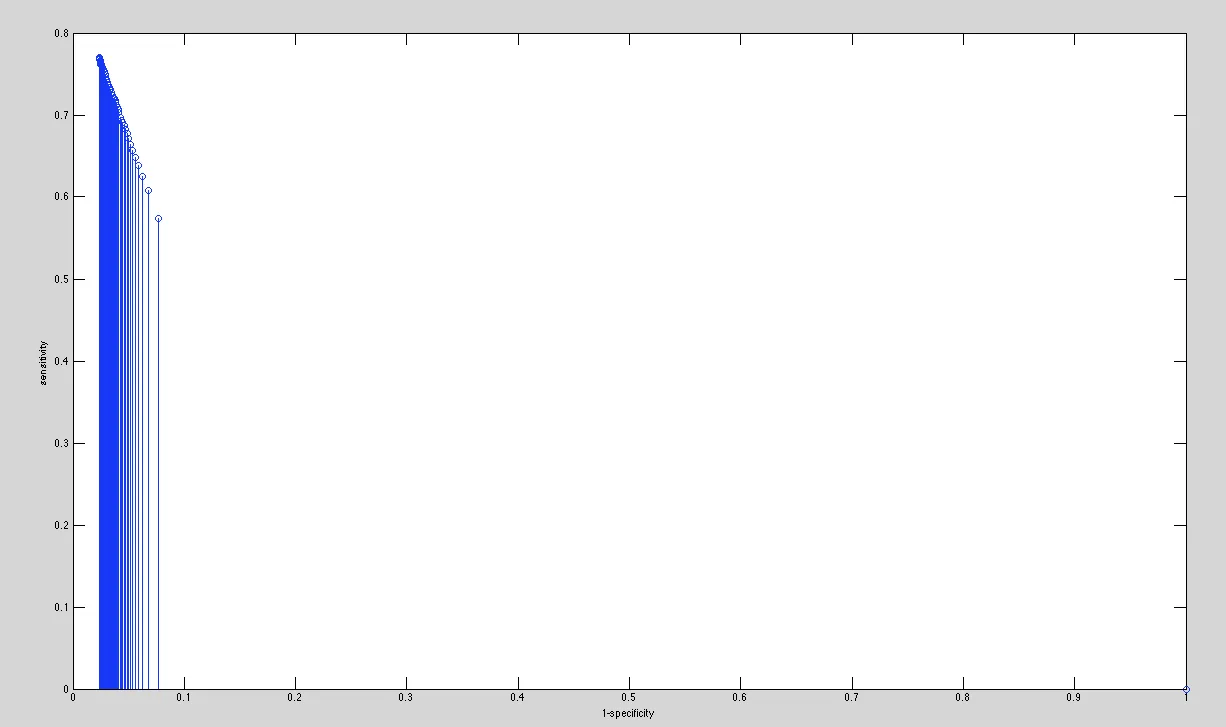
我错了,但我不知道错在哪里。也许我在分类器的结果小于阈值时计算FP、FN、TP、TN等方面出现了问题,因此我有一个丢弃。当有丢弃时,我应该增加什么?
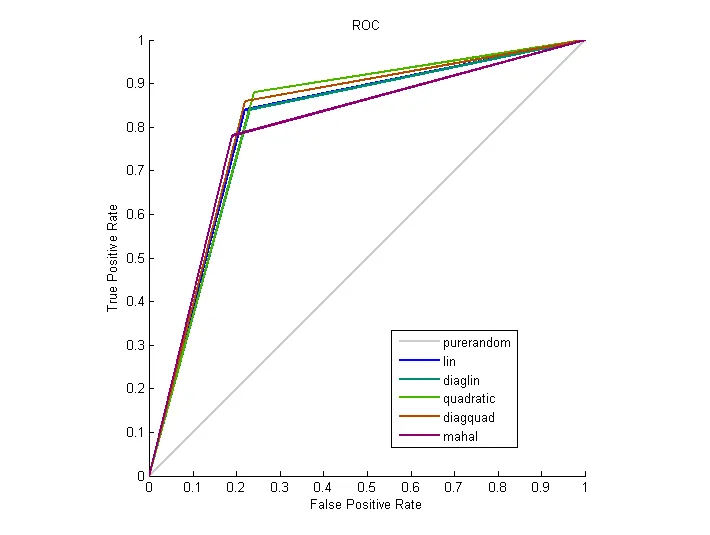 您可以注意到代码中我将“myinput”和“myoutput”堆叠在一起并将它们作为输入馈送到“plotroc”函数中。您应该将分类器的结果作为目标值和实际值,并且可以获得类似的结果。这比较了您的分类器的实际输出与目标值的理想输出。那些是plotroc的输入。
您可以注意到代码中我将“myinput”和“myoutput”堆叠在一起并将它们作为输入馈送到“plotroc”函数中。您应该将分类器的结果作为目标值和实际值,并且可以获得类似的结果。这比较了您的分类器的实际输出与目标值的理想输出。那些是plotroc的输入。