虽然已经过去了一年半,但我也需要一次性对多个pandas数据框列进行.transform()操作(并且还能够进行.inverse_transform()操作)。这进一步扩展了@PriceHardman的出色建议:
class MultiColumnLabelEncoder(LabelEncoder):
"""
Wraps sklearn LabelEncoder functionality for use on multiple columns of a
pandas dataframe.
"""
def __init__(self, columns=None):
self.columns = columns
def fit(self, dframe):
"""
Fit label encoder to pandas columns.
Access individual column classes via indexig `self.all_classes_`
Access individual column encoders via indexing
`self.all_encoders_`
"""
if self.columns is not None:
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
self.all_encoders_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
le = LabelEncoder()
le.fit(dframe.loc[:, column].values)
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
self.all_encoders_[idx] = le
else:
self.columns = dframe.iloc[:, :].columns
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
le = LabelEncoder()
le.fit(dframe.loc[:, column].values)
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
self.all_encoders_[idx] = le
return self
def fit_transform(self, dframe):
"""
Fit label encoder and return encoded labels.
Access individual column classes via indexing
`self.all_classes_`
Access individual column encoders via indexing
`self.all_encoders_`
Access individual column encoded labels via indexing
`self.all_labels_`
"""
if self.columns is not None:
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
self.all_encoders_ = np.ndarray(shape=self.columns.shape,
dtype=object)
self.all_labels_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
le = LabelEncoder()
dframe.loc[:, column] =\
le.fit_transform(dframe.loc[:, column].values)
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
self.all_encoders_[idx] = le
self.all_labels_[idx] = le
else:
self.columns = dframe.iloc[:, :].columns
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
le = LabelEncoder()
dframe.loc[:, column] = le.fit_transform(
dframe.loc[:, column].values)
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
self.all_encoders_[idx] = le
return dframe.loc[:, self.columns].values
def transform(self, dframe):
"""
Transform labels to normalized encoding.
"""
if self.columns is not None:
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[
idx].transform(dframe.loc[:, column].values)
else:
self.columns = dframe.iloc[:, :].columns
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[idx]\
.transform(dframe.loc[:, column].values)
return dframe.loc[:, self.columns].values
def inverse_transform(self, dframe):
"""
Transform labels back to original encoding.
"""
if self.columns is not None:
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[idx]\
.inverse_transform(dframe.loc[:, column].values)
else:
self.columns = dframe.iloc[:, :].columns
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[idx]\
.inverse_transform(dframe.loc[:, column].values)
return dframe.loc[:, self.columns].values
示例:
如果 df 和 df_copy() 是混合类型的 pandas 数据帧,您可以按以下方式将 MultiColumnLabelEncoder() 应用于 dtype=object 列:
df_object_columns = df.iloc[:, :].select_dtypes(include=['object']).columns
df_copy_object_columns = df_copy.iloc[:, :].select_dtypes(include=['object']).columns
mcle = MultiColumnLabelEncoder(columns=object_columns)
mcle.fit(df)
mcle.transform(df)
array([[1, 0, 0, ..., 1, 1, 0],
[0, 5, 1, ..., 1, 1, 2],
[1, 1, 1, ..., 1, 1, 2],
...,
[3, 5, 1, ..., 1, 1, 2],
mcle.transform(df_copy)
array([[1, 0, 0, ..., 1, 1, 0],
[0, 5, 1, ..., 1, 1, 2],
[1, 1, 1, ..., 1, 1, 2],
...,
[3, 5, 1, ..., 1, 1, 2],
mcle.inverse_transform(df)
array([['August', 'Friday', '2013', ..., 'N', 'N', 'CA'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['August', 'Monday', '2014', ..., 'N', 'N', 'NJ'],
...,
['February', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['March', 'Tuesday', '2013', ..., 'N', 'N', 'NJ']], dtype=object)
mcle.inverse_transform(df_copy)
array([['August', 'Friday', '2013', ..., 'N', 'N', 'CA'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['August', 'Monday', '2014', ..., 'N', 'N', 'NJ'],
...,
['February', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['March', 'Tuesday', '2013', ..., 'N', 'N', 'NJ']], dtype=object)
您可以通过索引访问用于拟合每个列的单独列类、列标签和列编码器:
mcle.all_classes_
mcle.all_encoders_
mcle.all_labels_
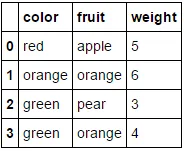 转换为
转换为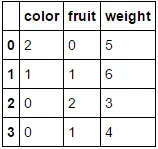
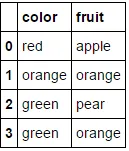 转换为
转换为 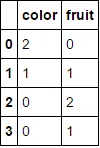 。
。
dataframe进行编码,我正在选择编码对象,因此希望避免对50个独立对象进行pickle/unpickle操作。另外,我想知道是否有一种方法可以让编码器简化数据,例如只返回每列中变量的唯一组合的一个标识符所在的行。 - Bryanreplace方法,在 pandas 中以简单的方式完成所有操作。请参见下面的答案。 - Ted Petrouscikit-learn 0.20开始,不需要实现自定义类来对多列进行标签编码。您可以直接使用OrdinalEncoder。 - Ric S